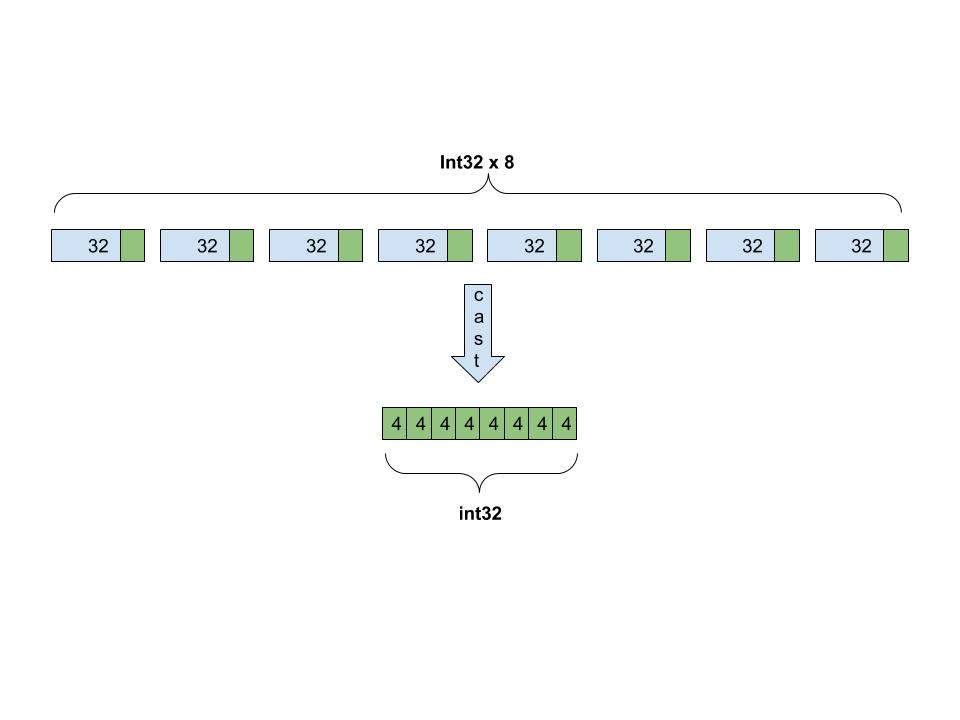
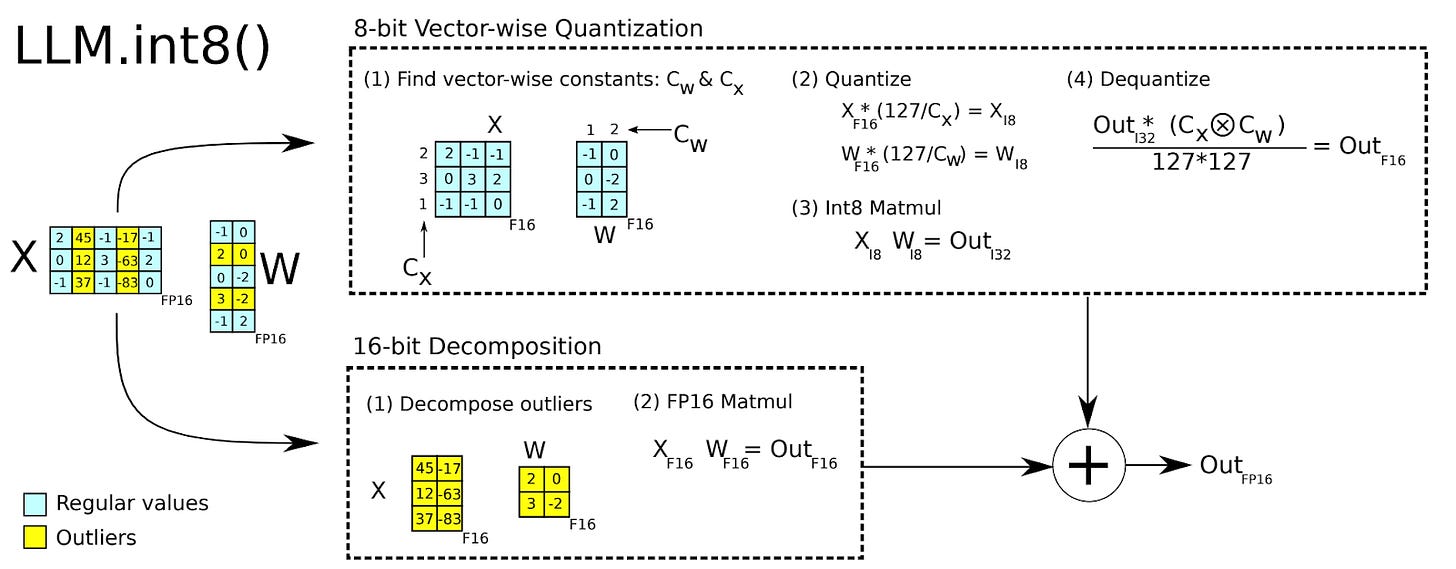
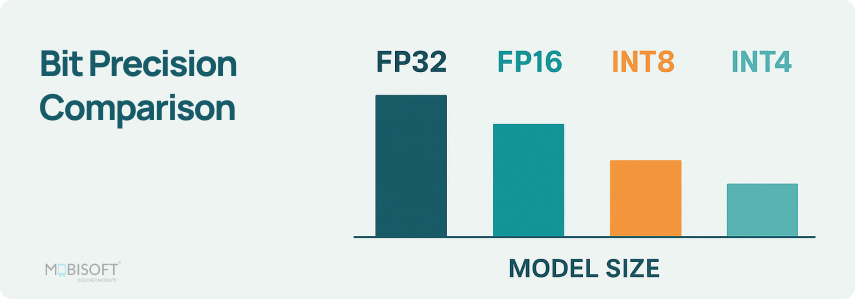
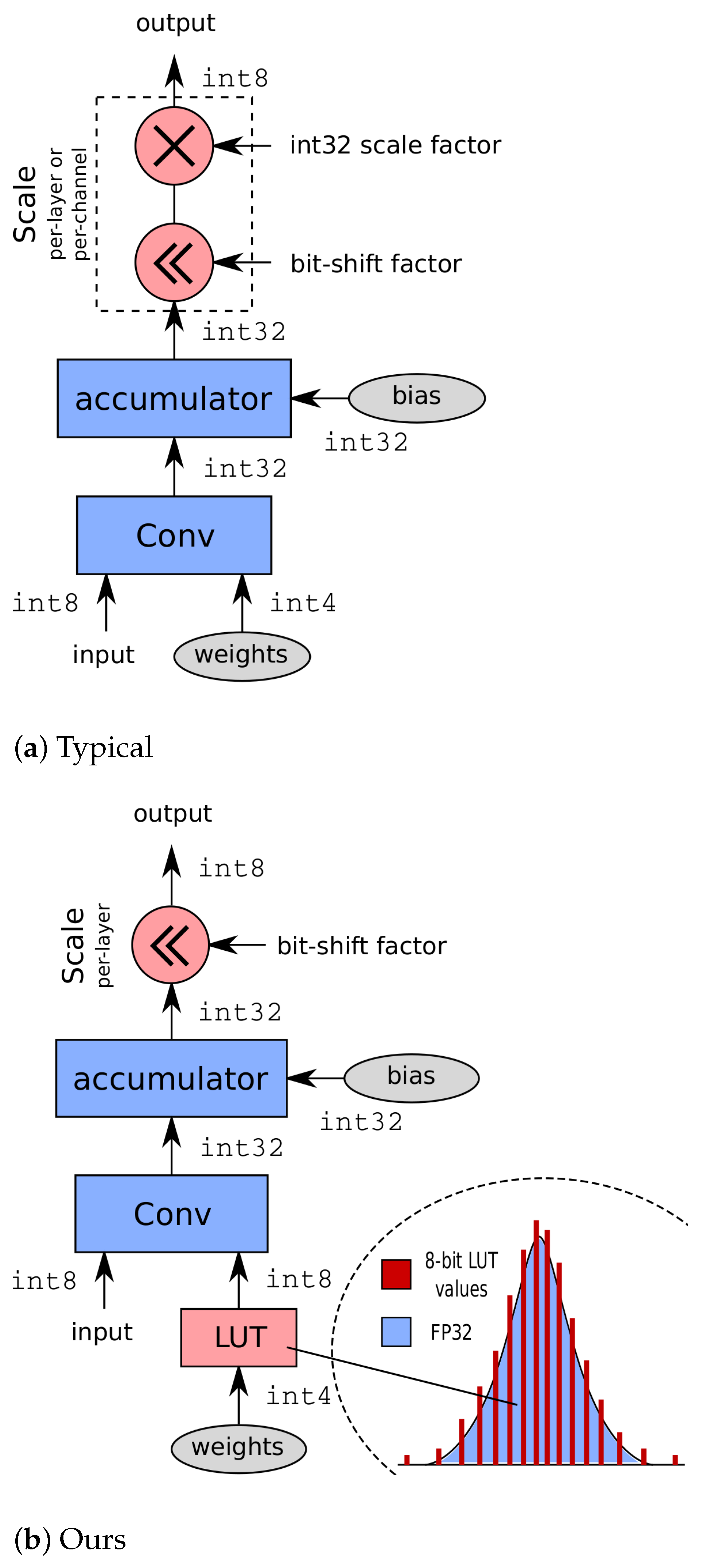
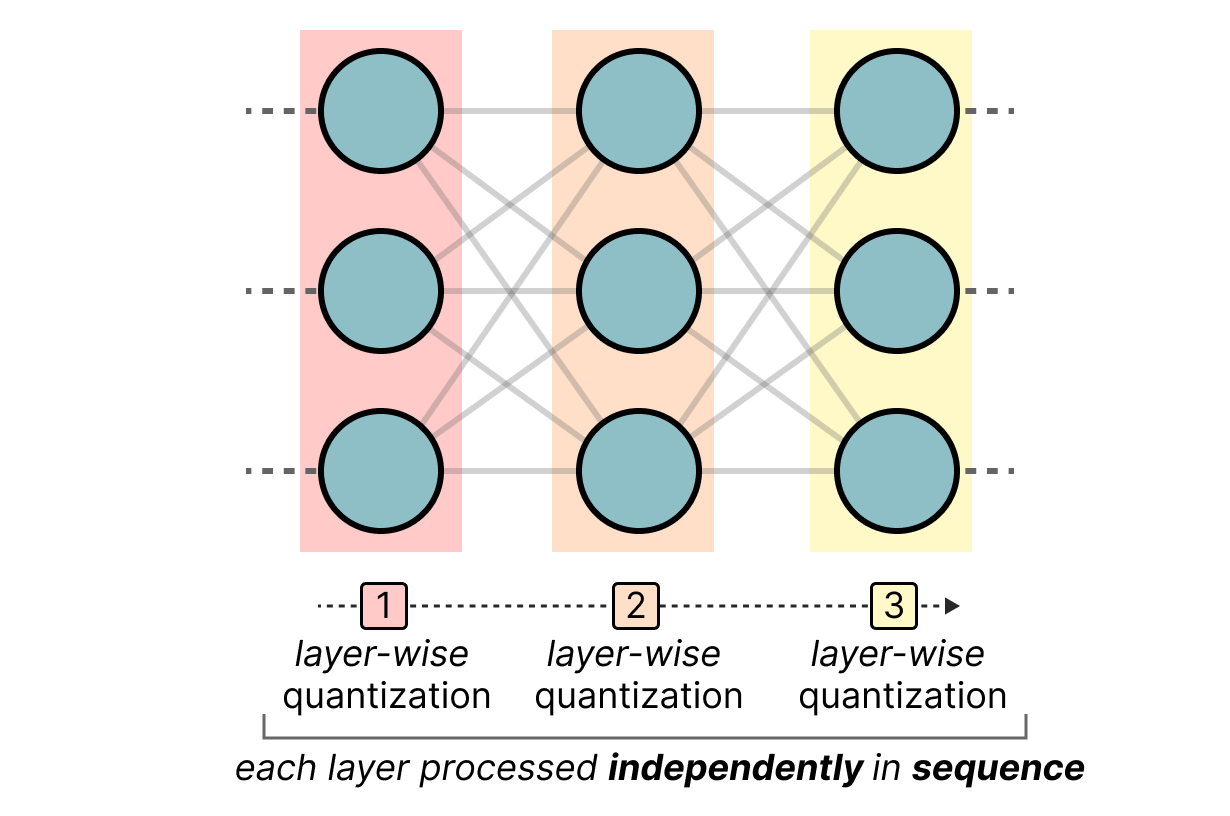
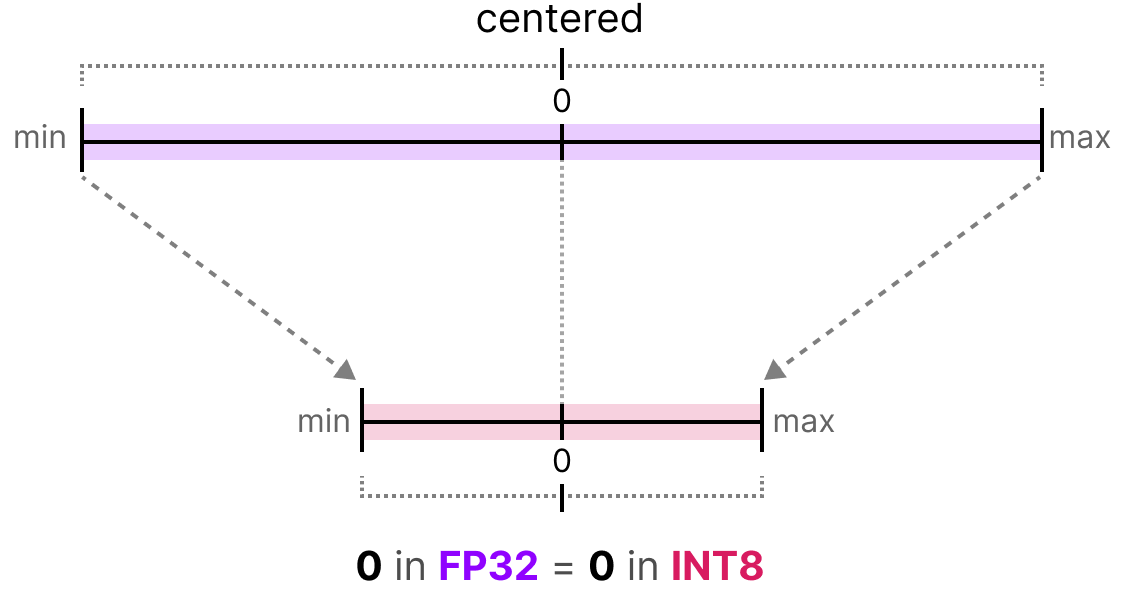
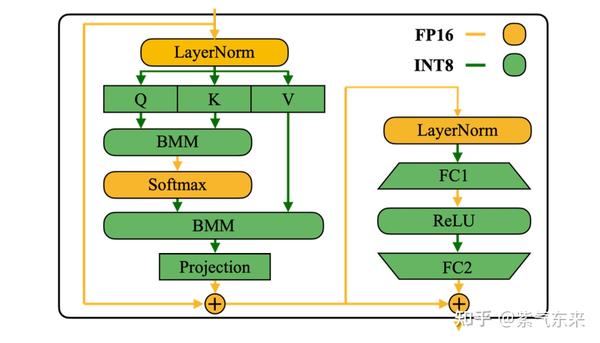
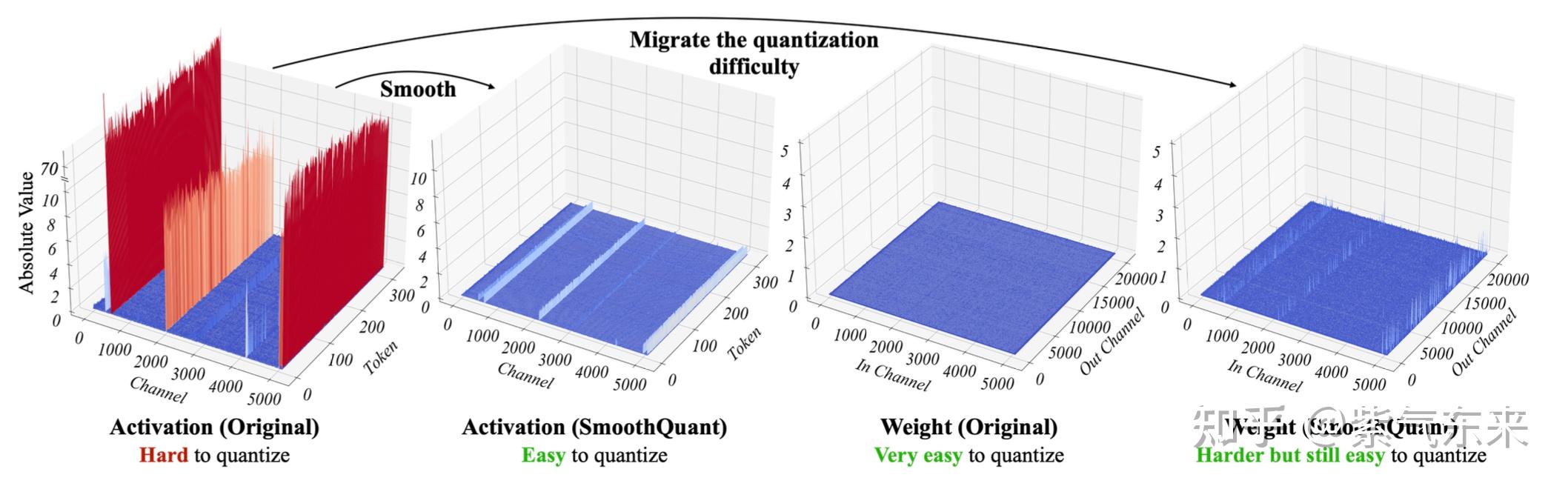
Showing 120 of 120on this page. Filters & sort apply to loaded results; URL updates for sharing.120 of 120 on this page
INT8 and INT4 Quantization ValueError · Issue #35 · moojink/openvla-oft ...
KV Cache INT8 and INT4 quantization precision reduction · Issue #772 ...
Could you upload the INT4 quantization and INT8 quantization model to ...
[2301.12017] Understanding INT4 Quantization for Language Models ...
(PDF) Understanding INT4 Quantization for Transformer Models: Latency ...
What Is int8 Quantization and Why Is It Popular for Deep Neural ...
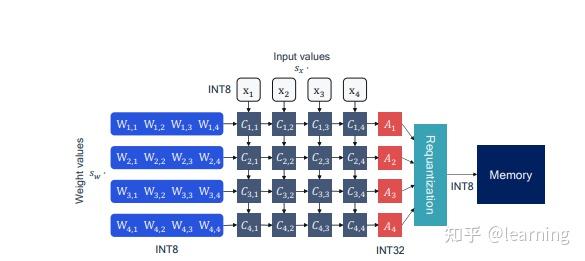
INT8, INT4 and Other Integer Types for Quantization
Understanding Int4 scalar quantization in Lucene - Search Labs
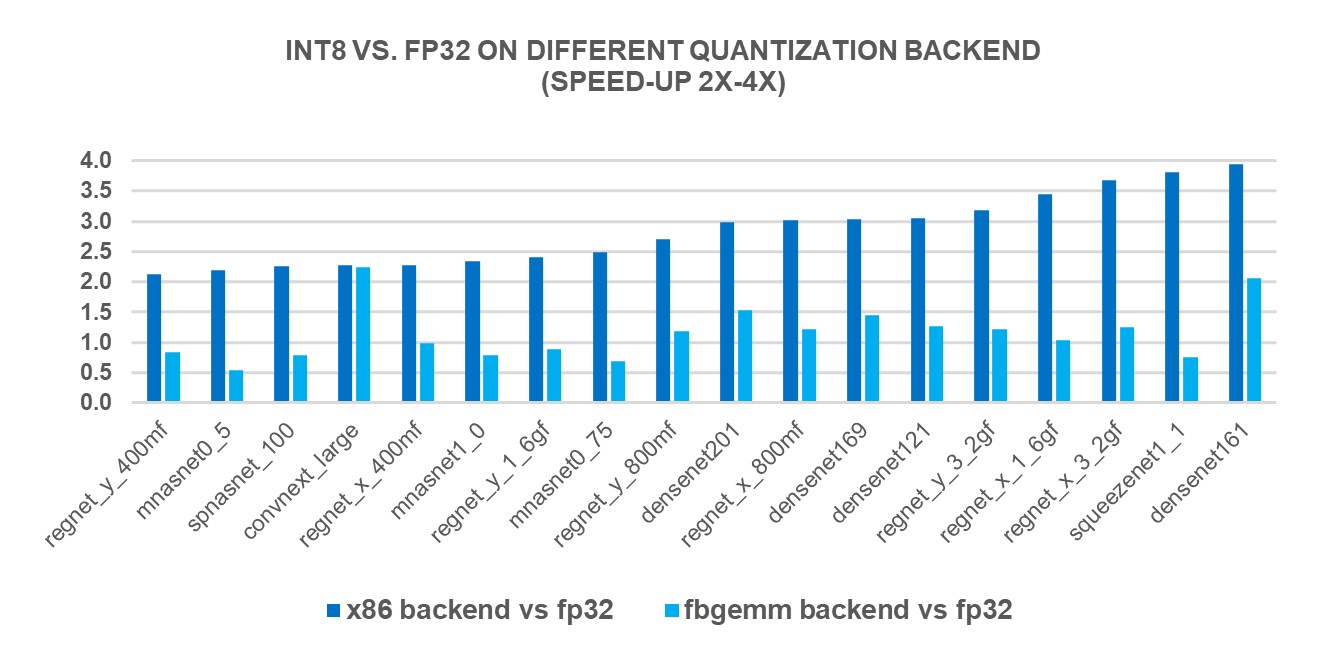
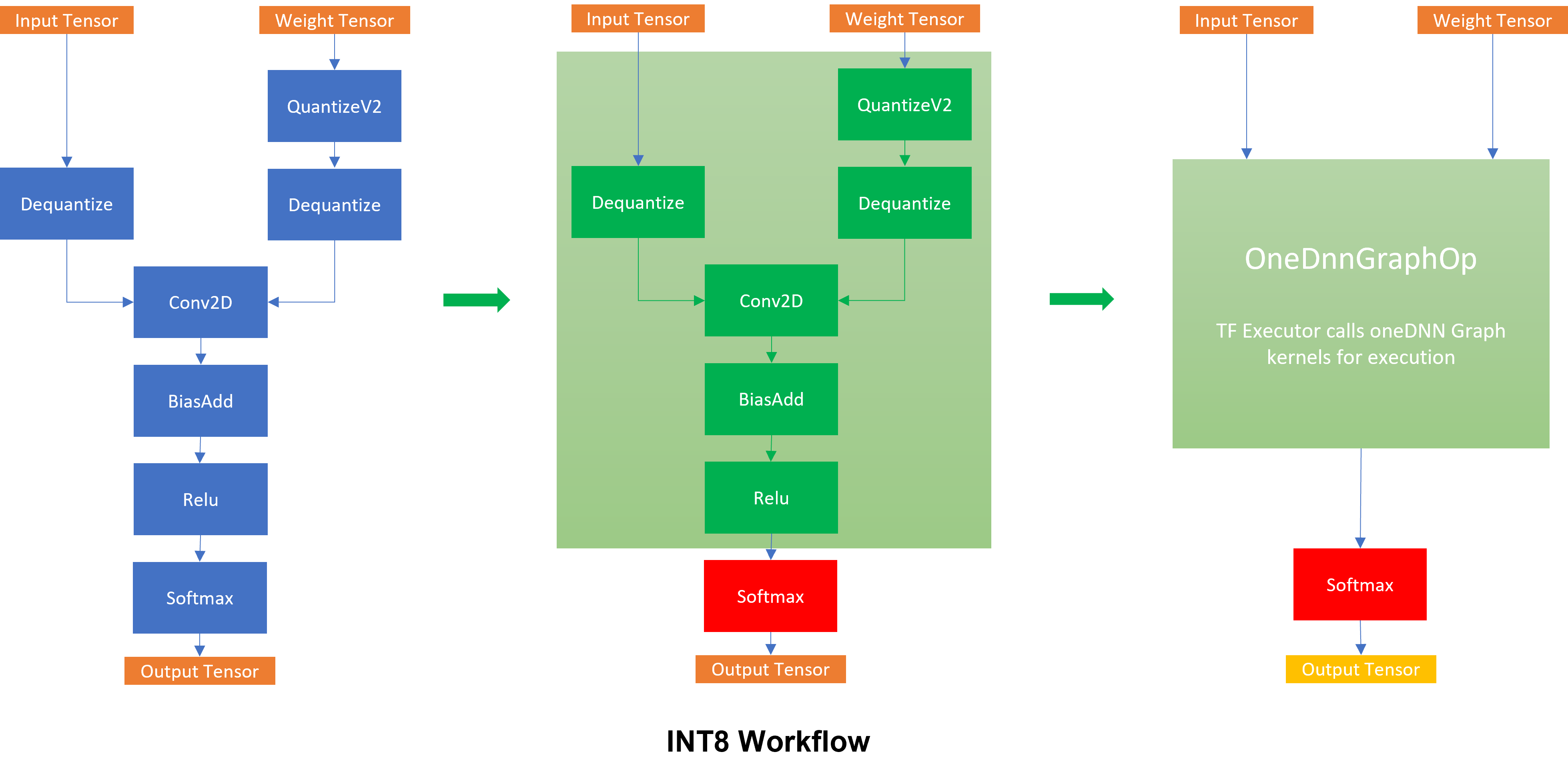
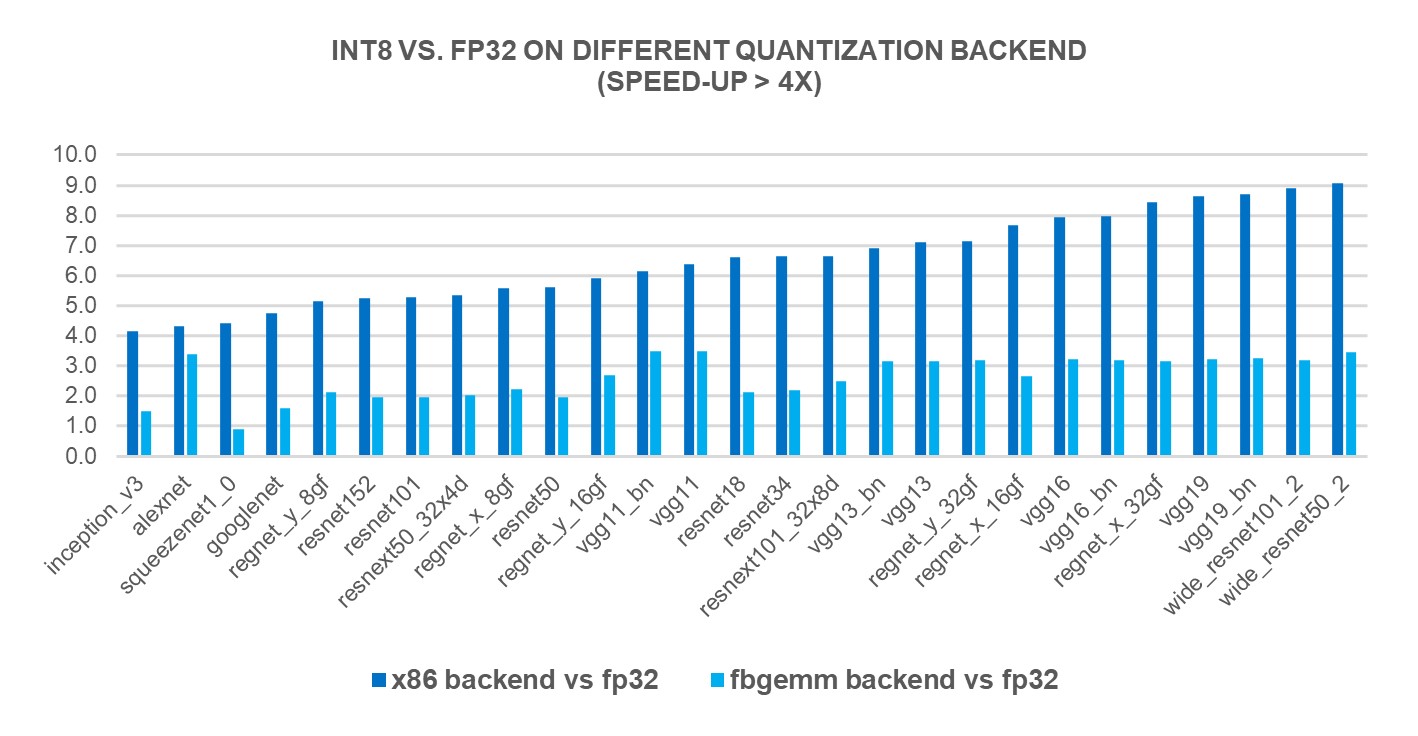
INT8 Quantization for x86 CPU in PyTorch | PyTorch
INT4 Quantization (with code demonstration)
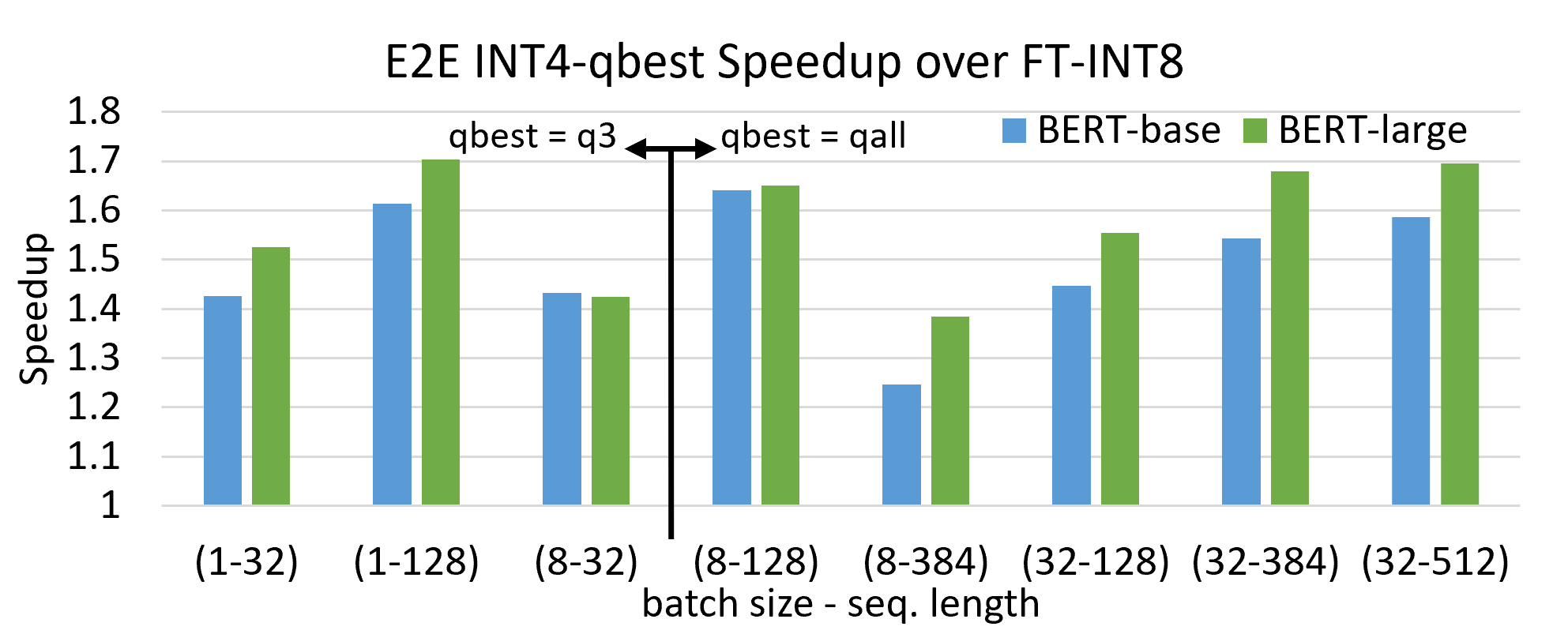
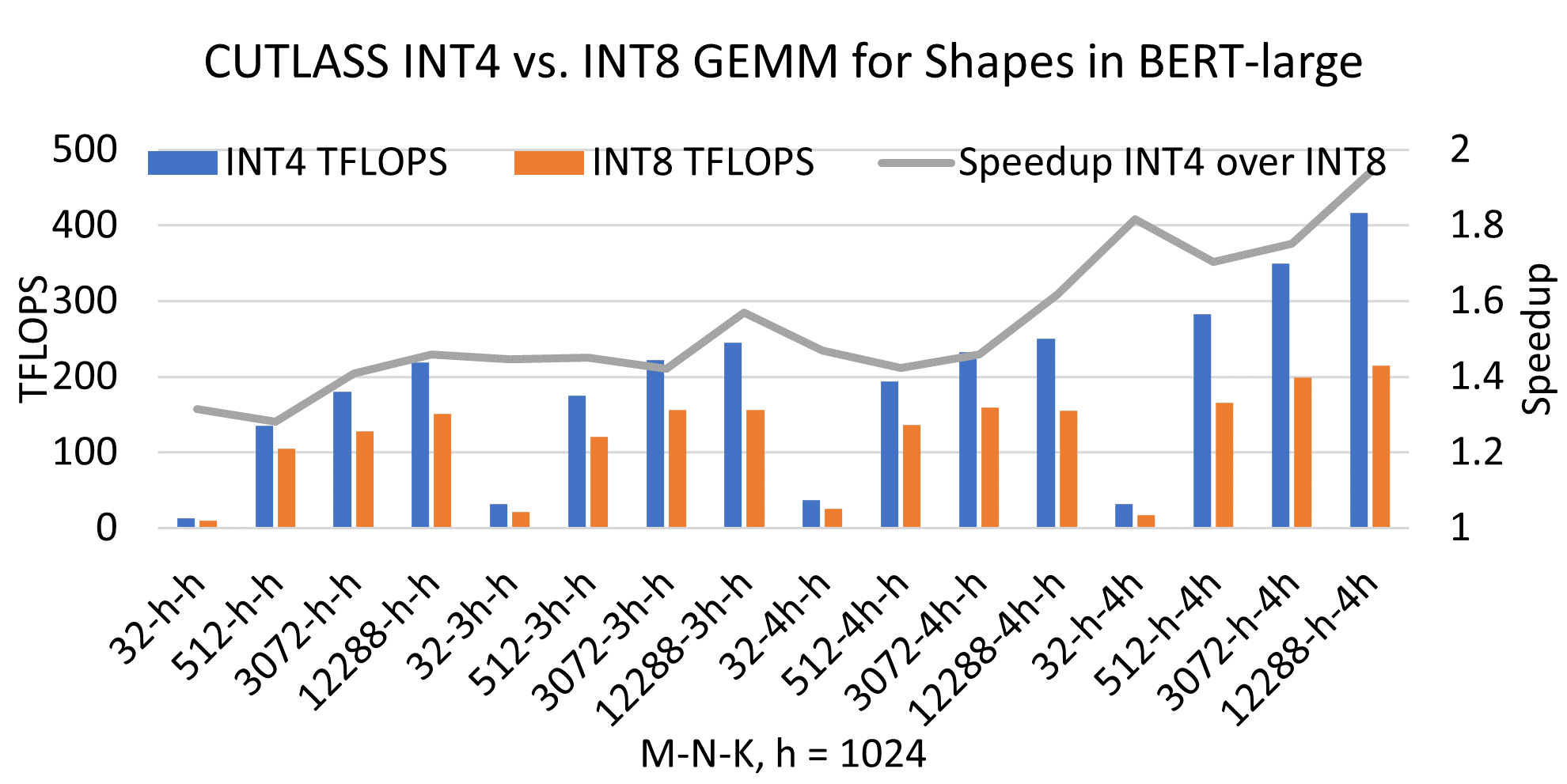
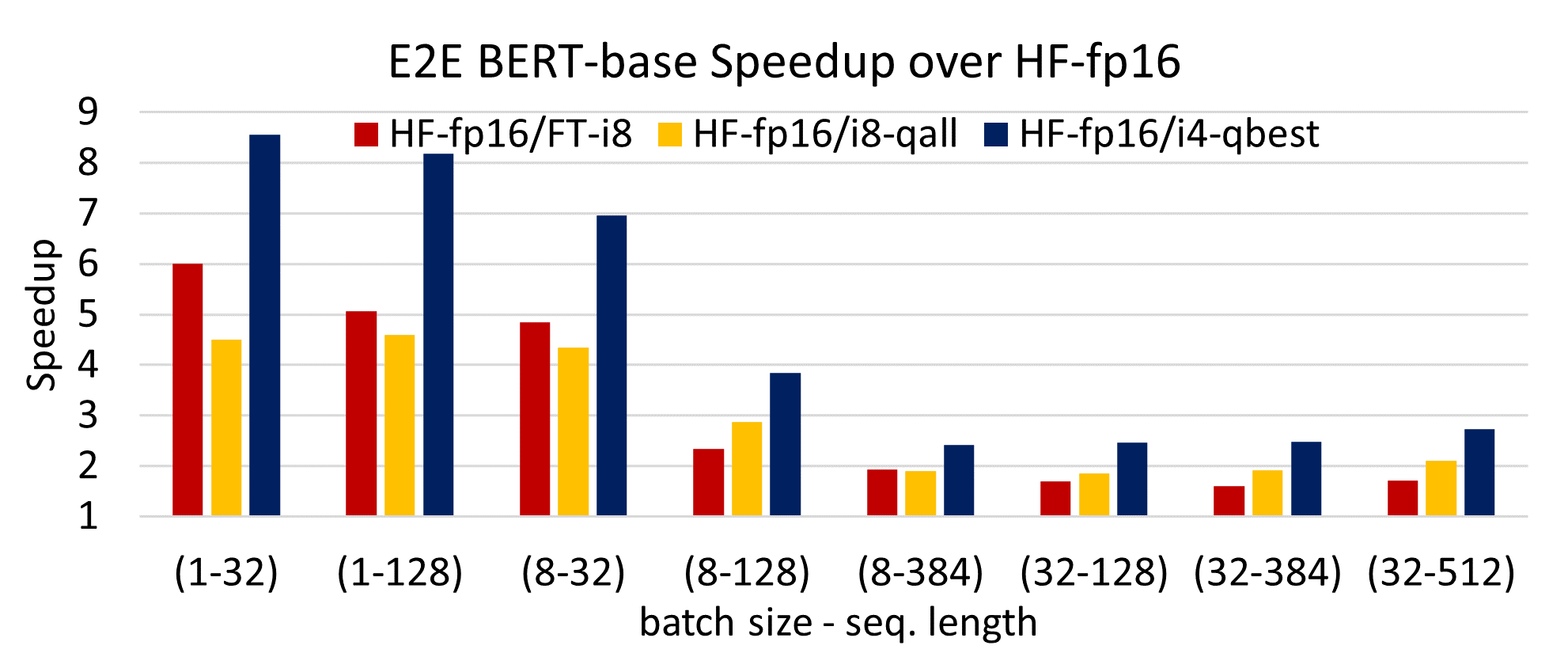
CUTLASS INT4 vs. INT8 GEMM performance comparison across different ...
INT8 Quantization — Intel® Extension for TensorFlow* 0.1.dev1+ge26b4db ...
面试官:为什么需要量化,为什么 int4 / int8 量化后大模型仍能保持性能? - 知乎
Can vllm support quantized INT4 and INT8 models? Whether there is a ...
INT8 Quantization Basics | Rand Xie
Understanding int8 neural network quantization - YouTube
Left: Unsigned INT4 quantization compared to unsigned FP4 2M2E ...
Understanding Int4 scalar quantization in Lucene — Search Labs ...
A Hands-On Walkthrough on Model Quantization - Medoid AI
Unlocking LLM Performance: Advanced Quantization Techniques on Dell ...
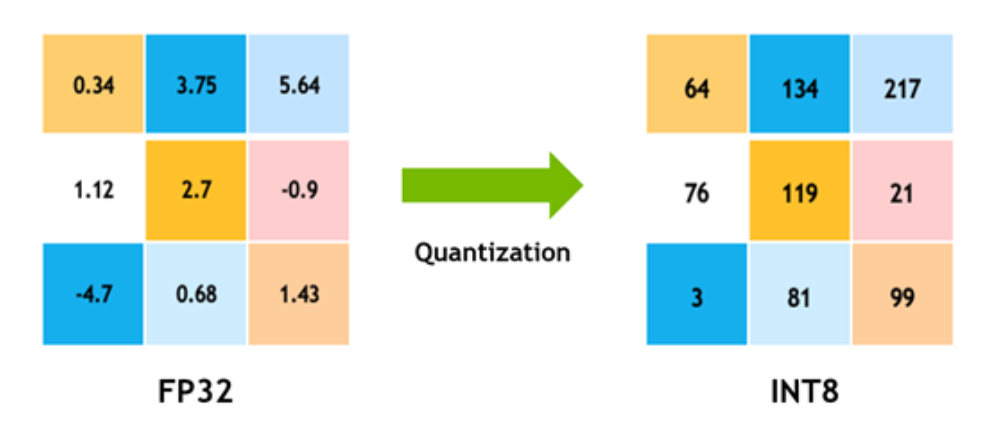
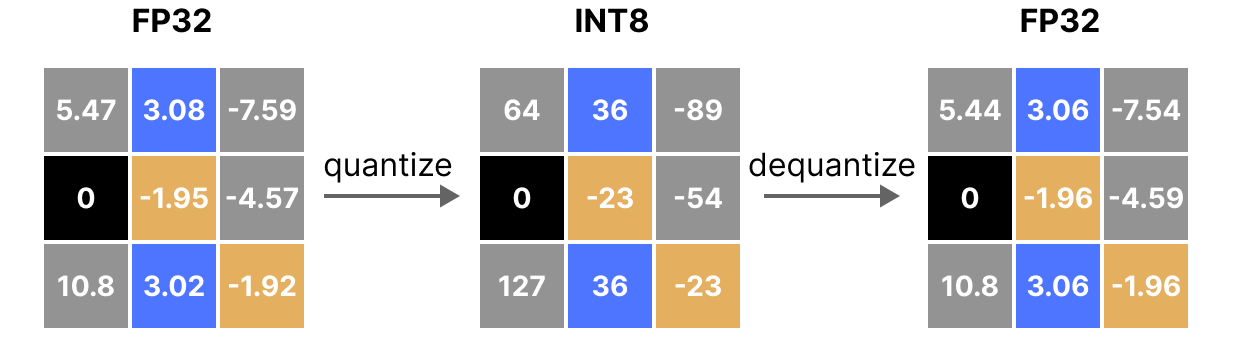
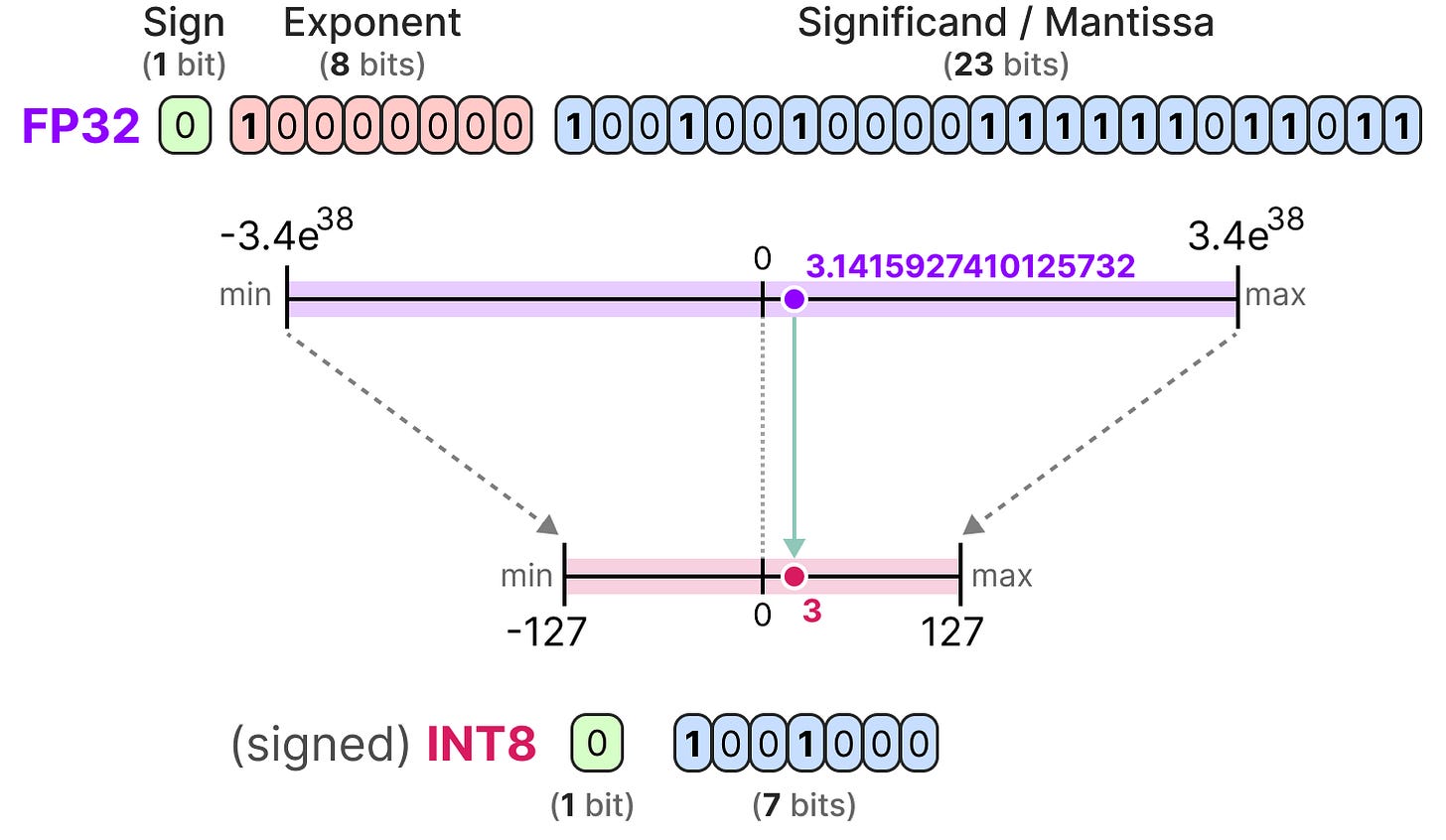
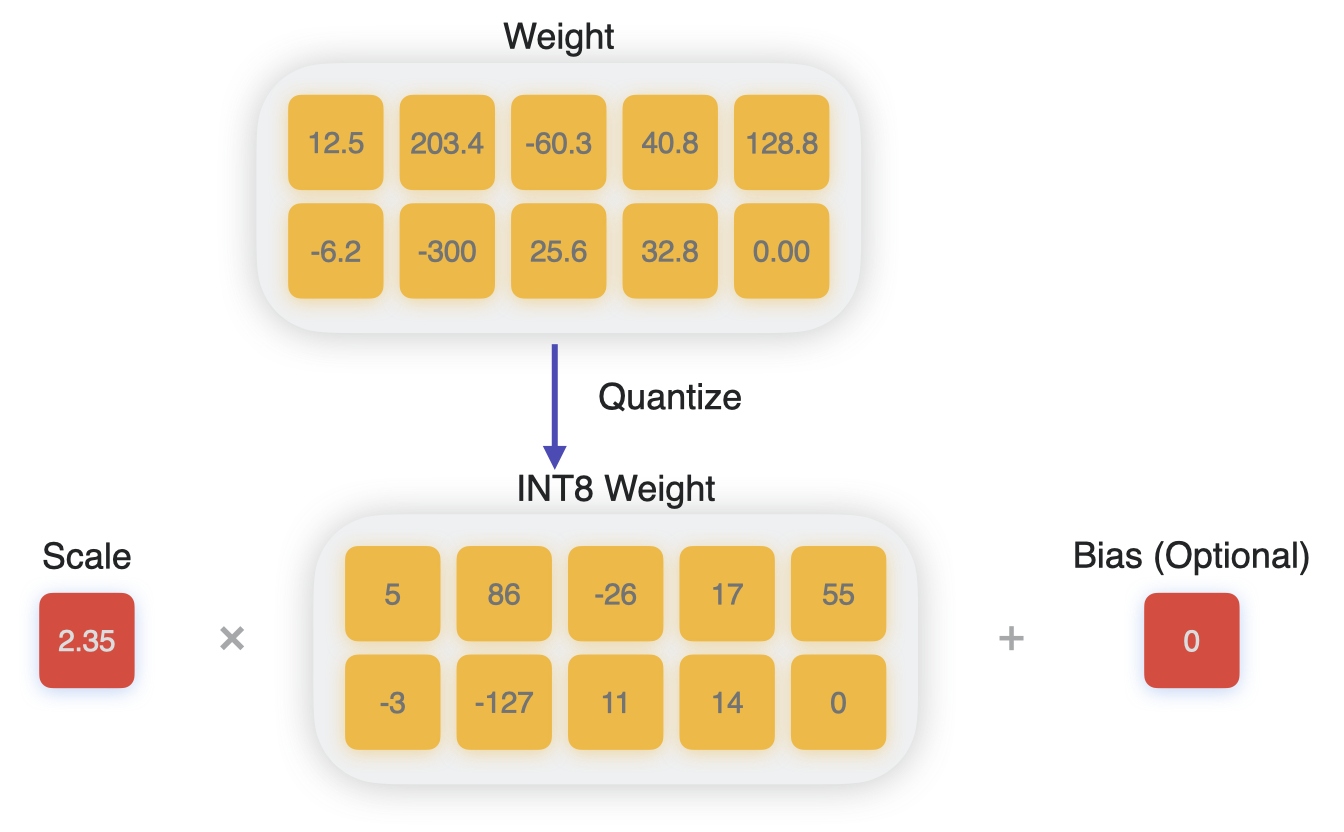
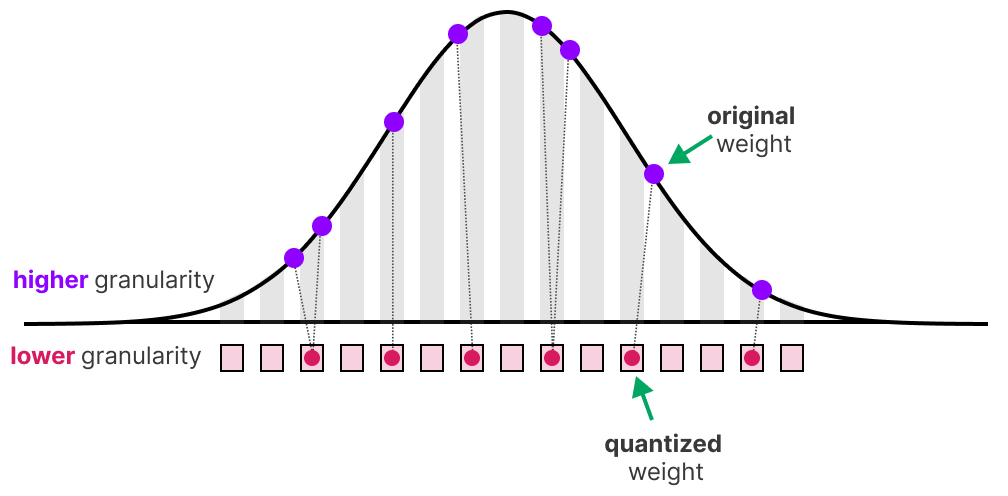
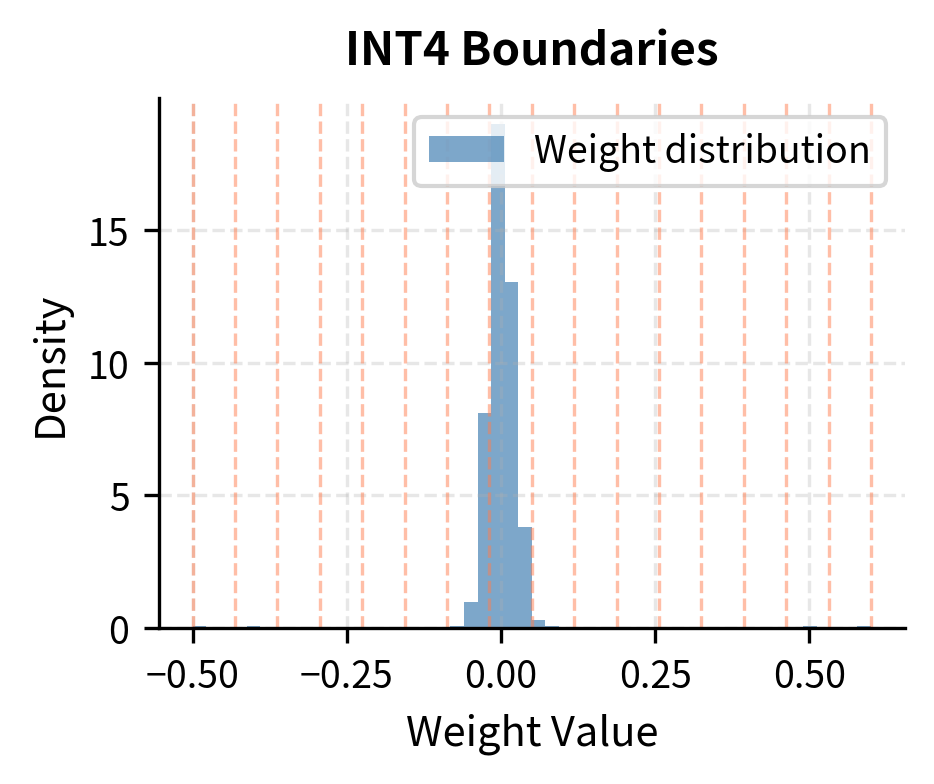
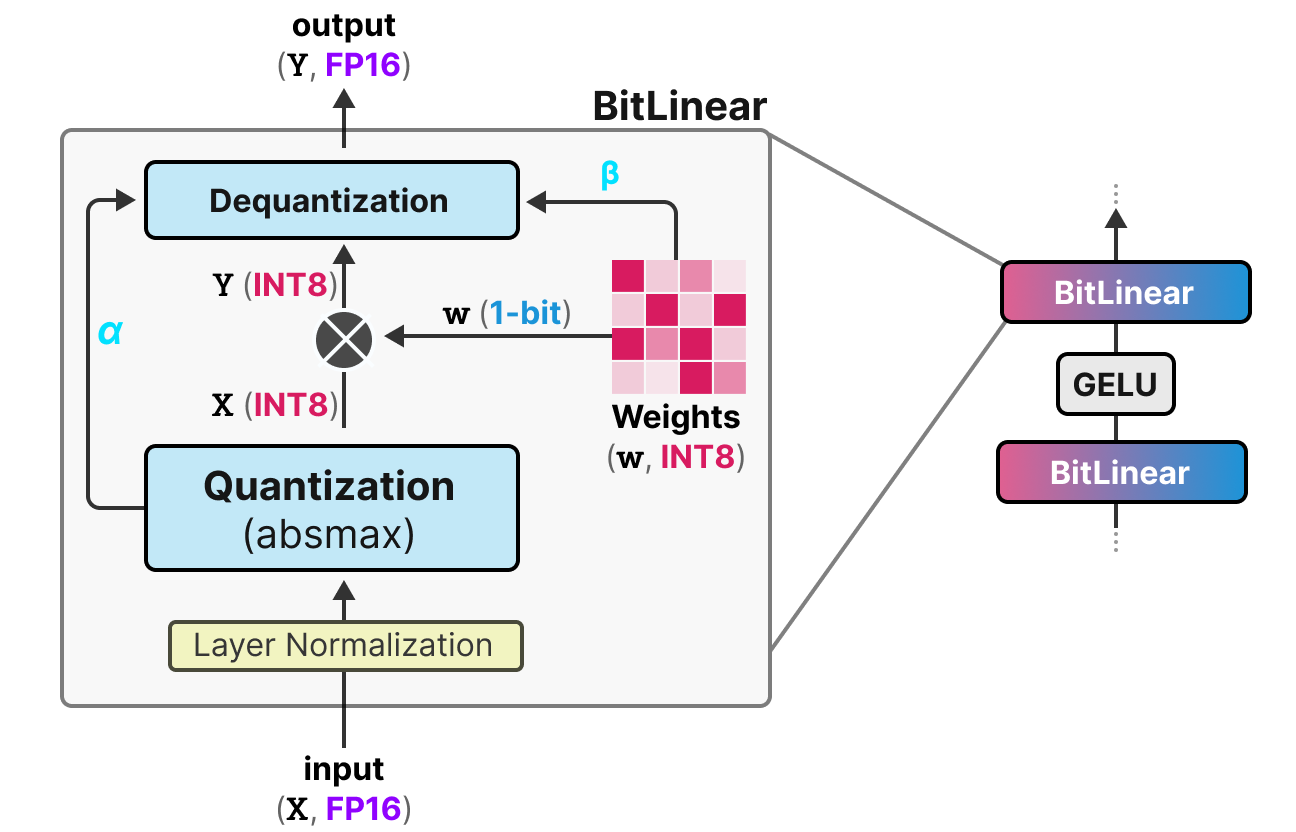
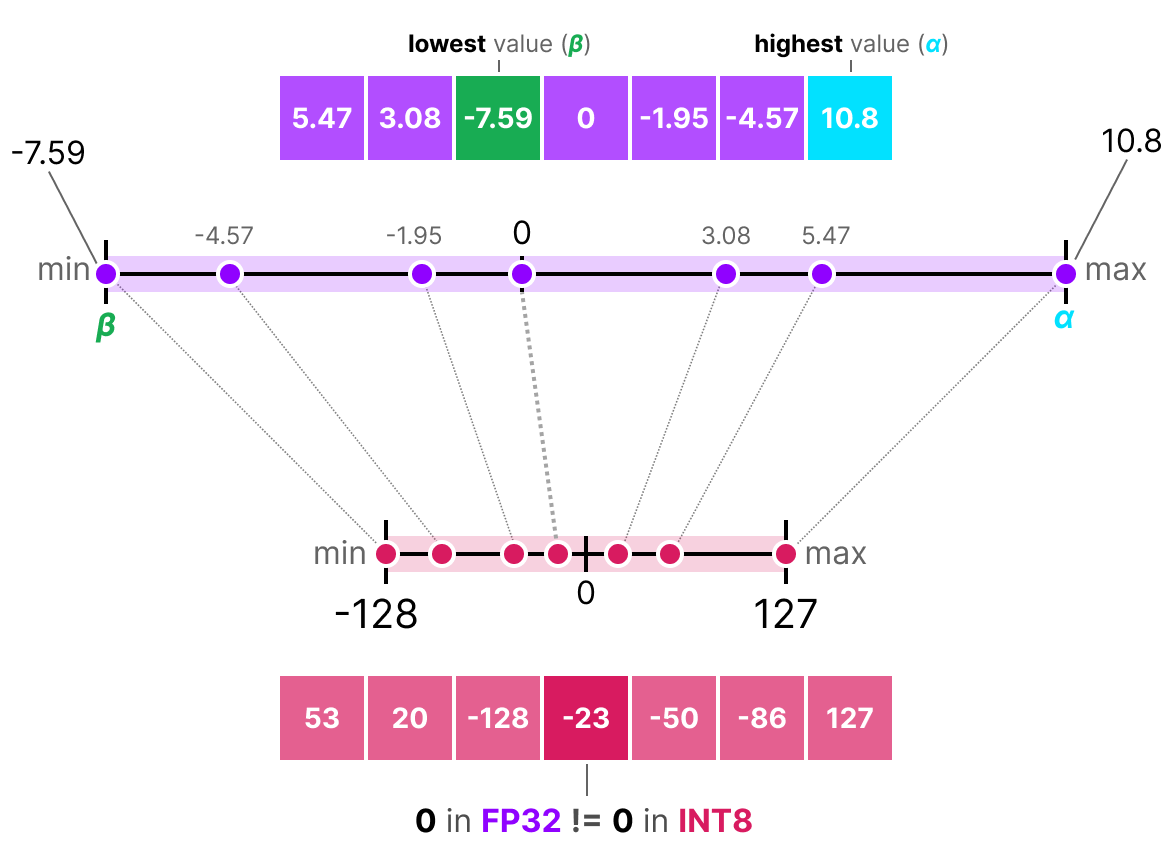
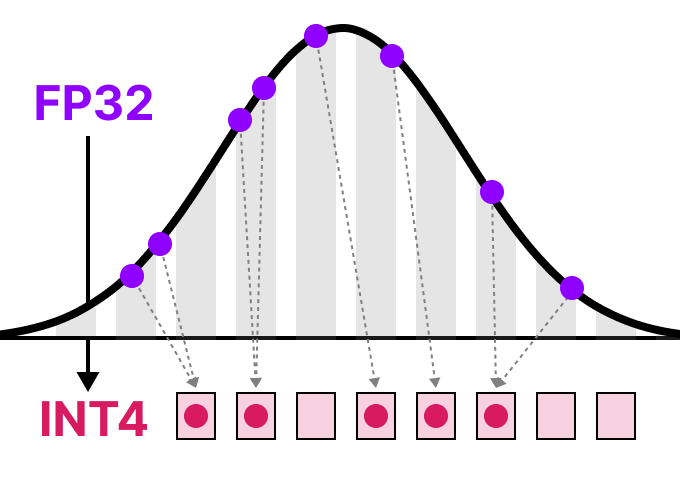
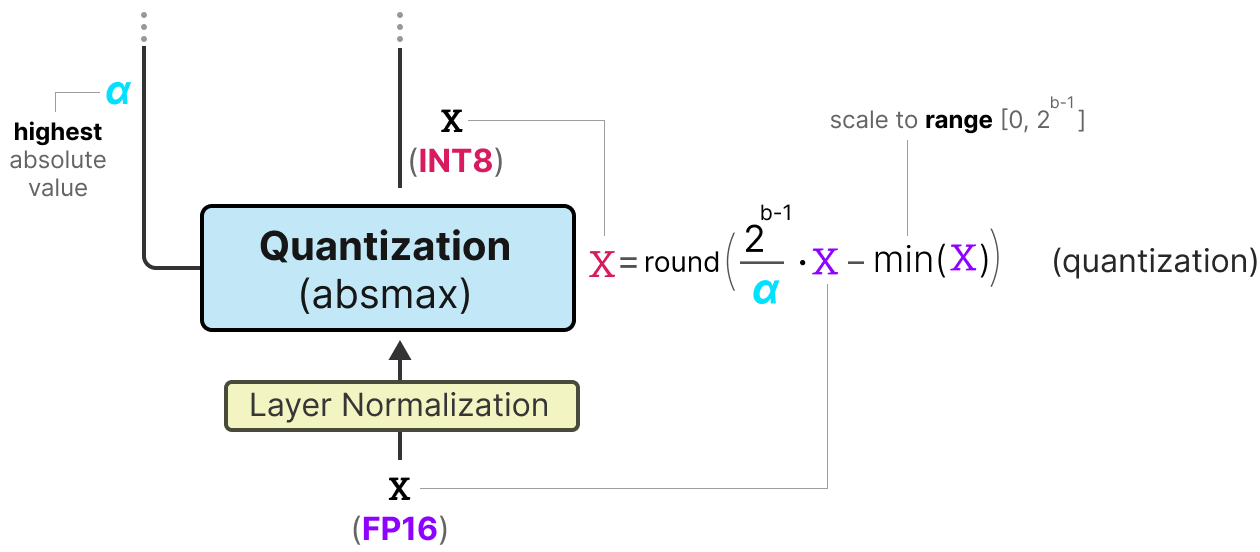
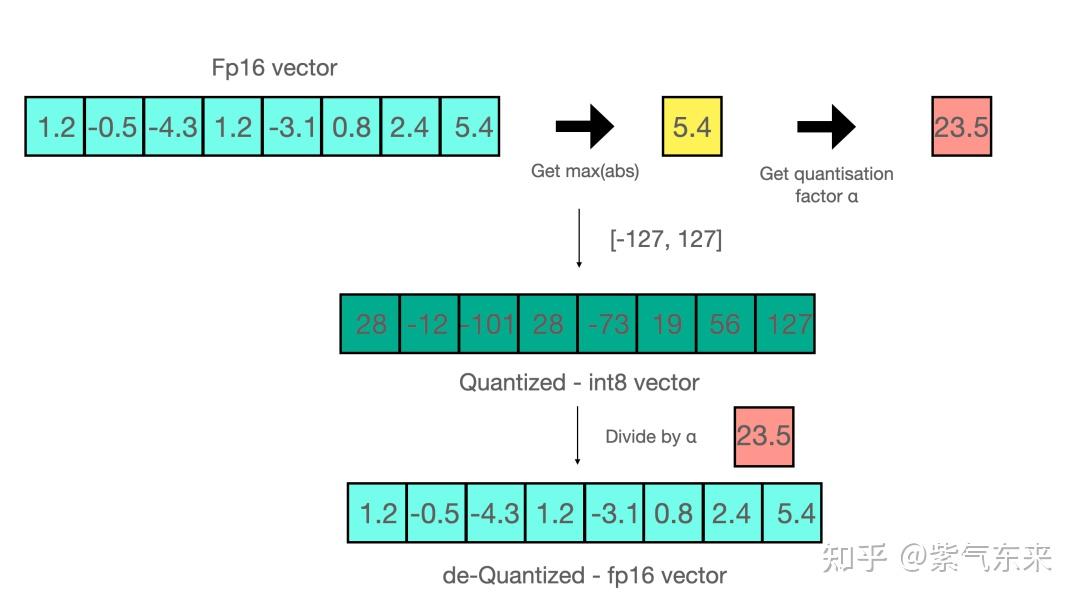
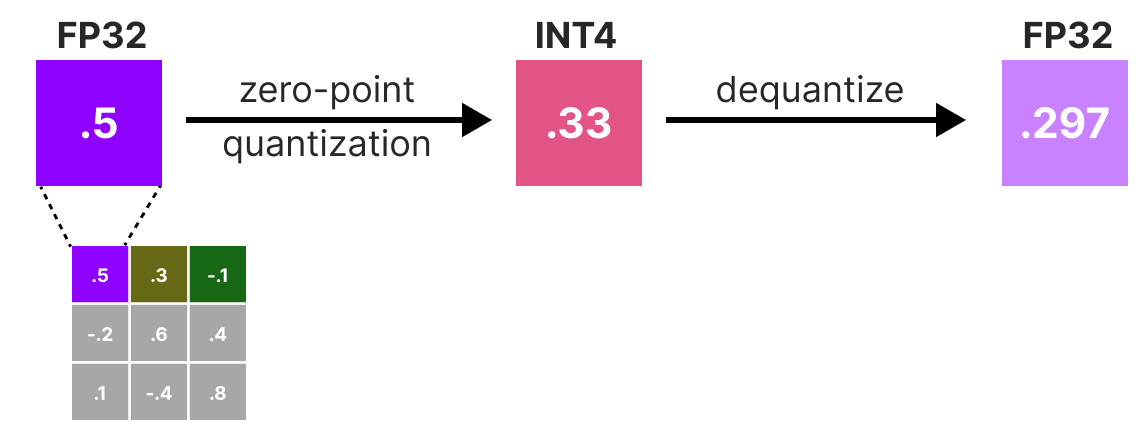
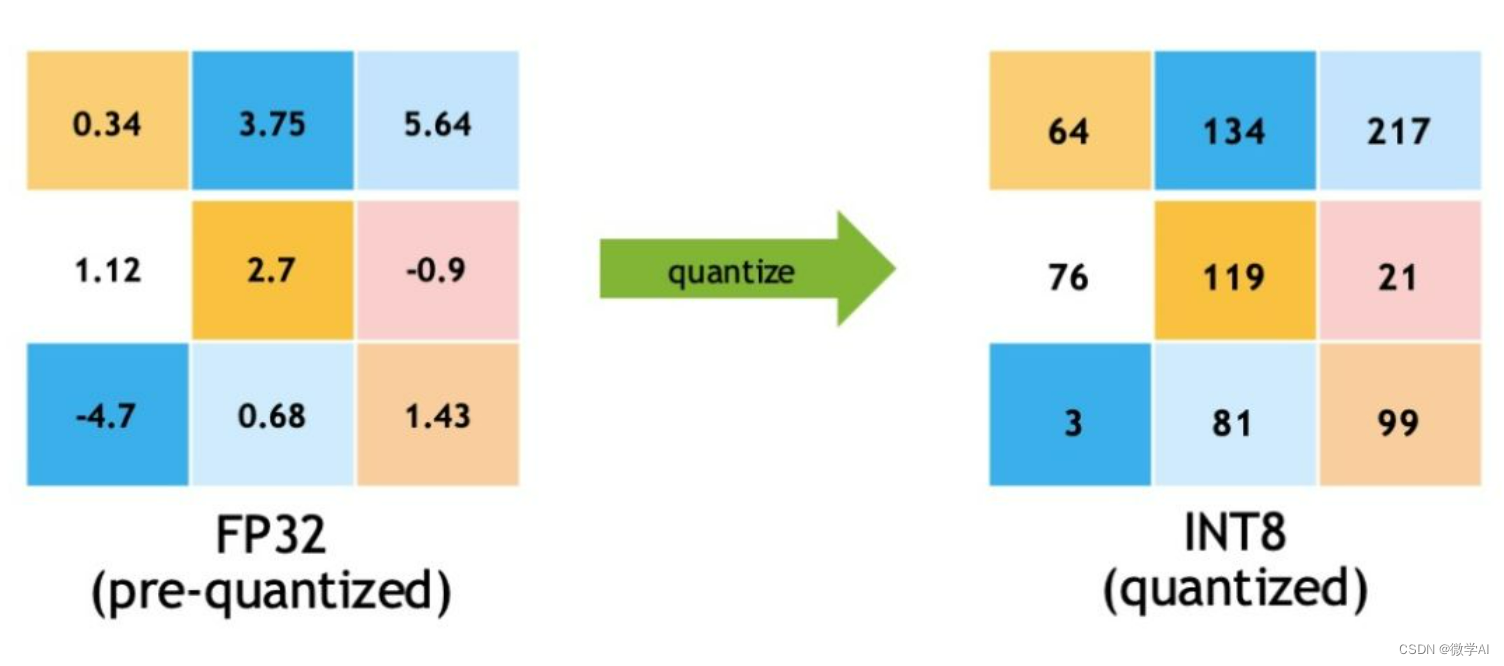
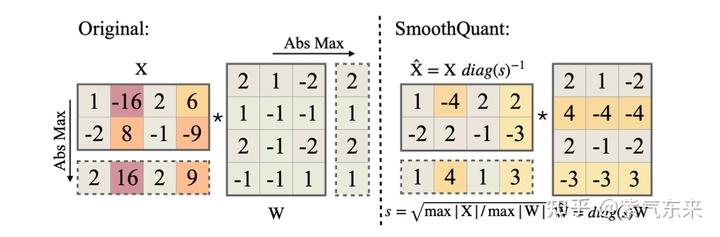
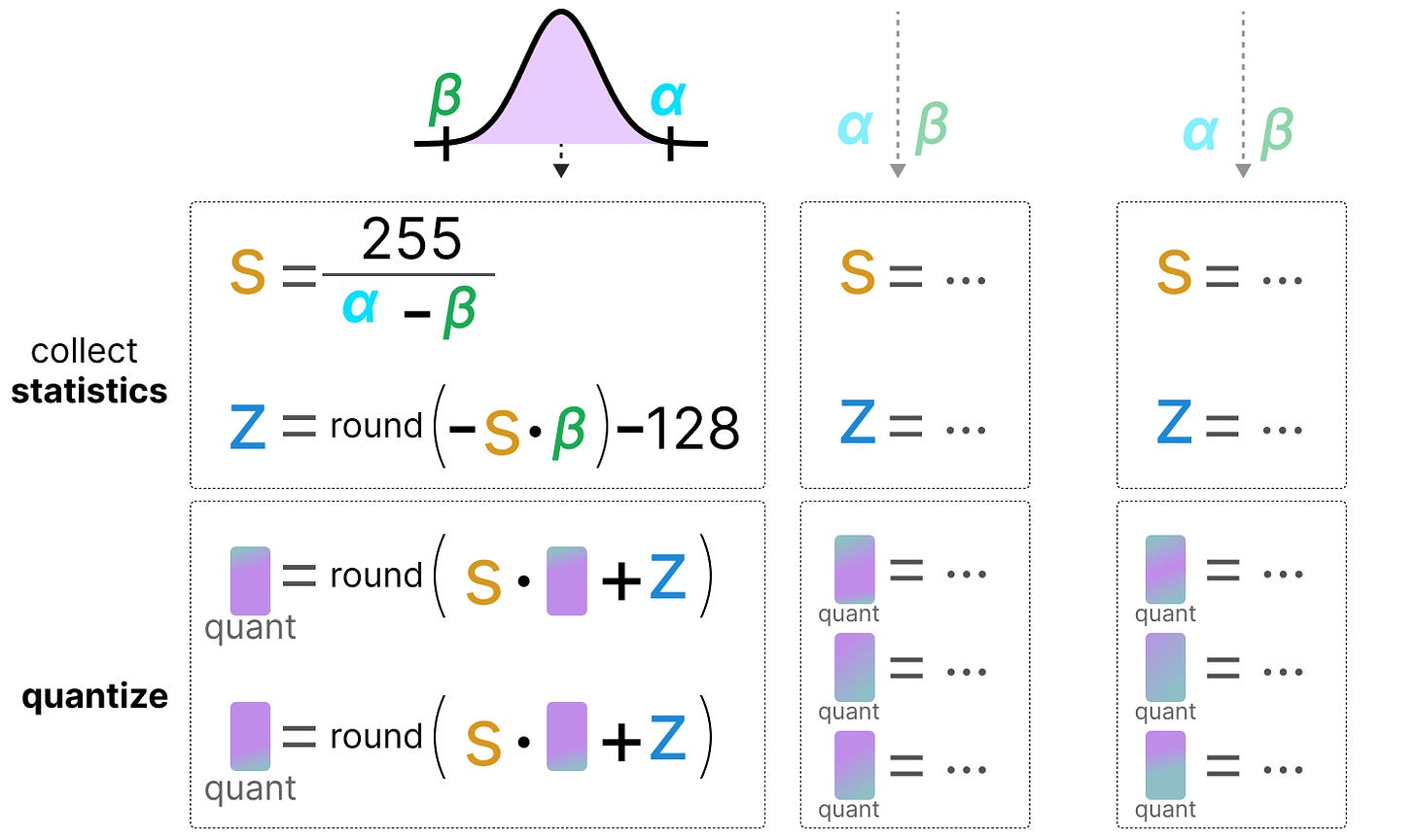
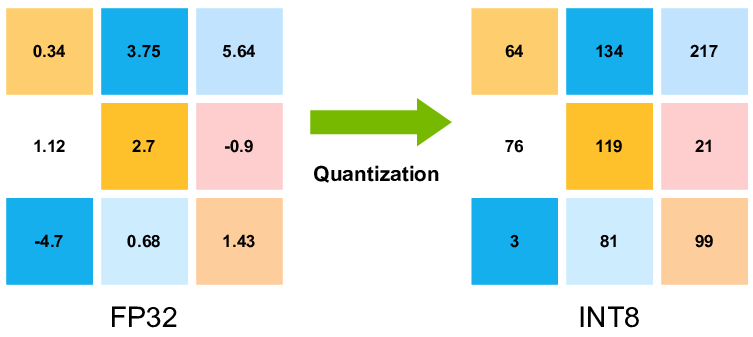
A Visual Guide to Quantization - by Maarten Grootendorst
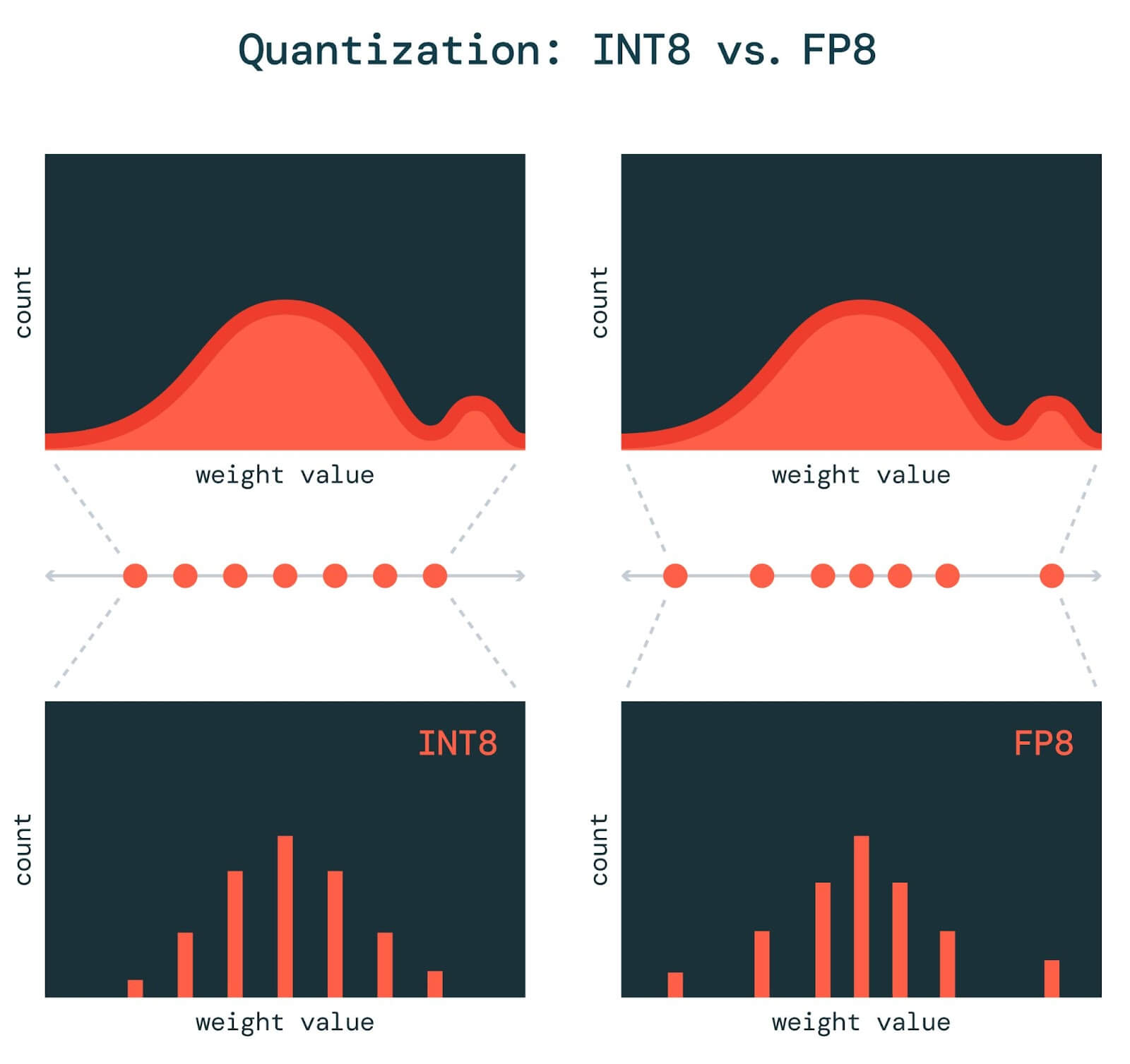
[2303.17951] FP8 versus INT8 for efficient deep learning inference
Quantization Methods for 100X Speedup in Large Language Model Inference
4-bit LLM training and Primer on Precision, data types & Quantization
Quantization Overview — Guide to Core ML Tools
[RFC][Tensorcore] INT4 end-to-end inference - pre-RFC - Apache TVM Discuss
Update #31: Expectations for AI + Healthcare and 8-bit Quantization
GitHub - intel/neural-compressor: SOTA low-bit LLM quantization (INT8 ...
What is Quantization in LLM? A Complete Guide to Optimizing AI
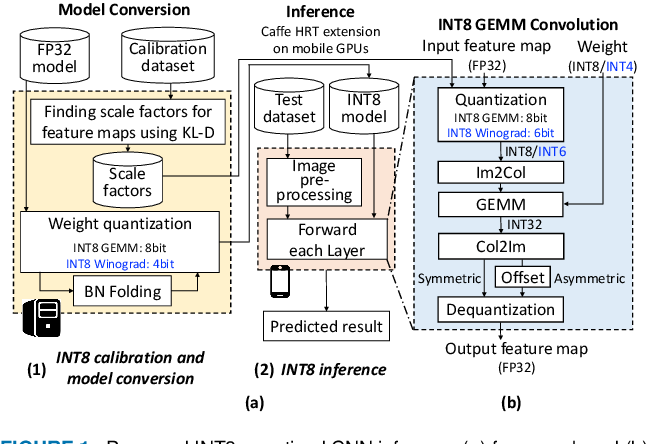
Integer-Only CNNs with 4 Bit Weights and Bit-Shift Quantization Scales ...
A Visual Guide to Quantization - Maarten Grootendorst
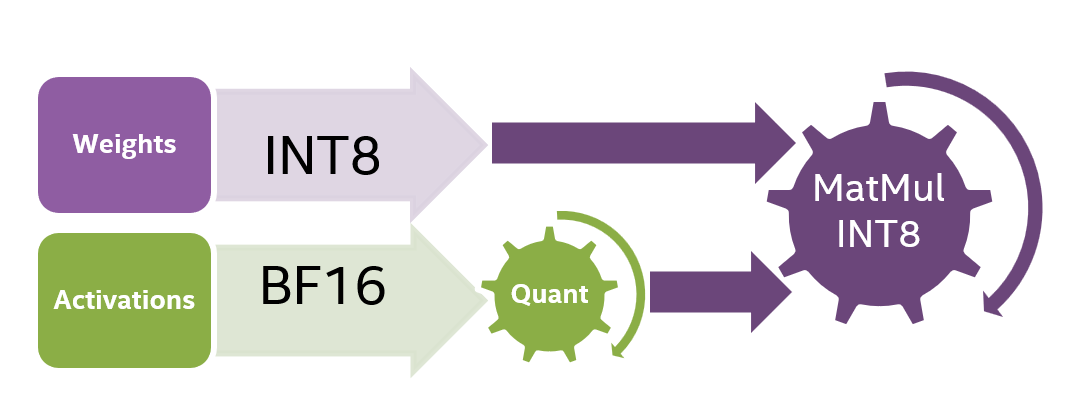
A Practical Guide to LLM Quantization (int8/int4) | Hivenet
INT4 Quantization: Group-wise Methods & NF4 Format for LLMs ...
Quark Quantized INT8 Models - a amd Collection
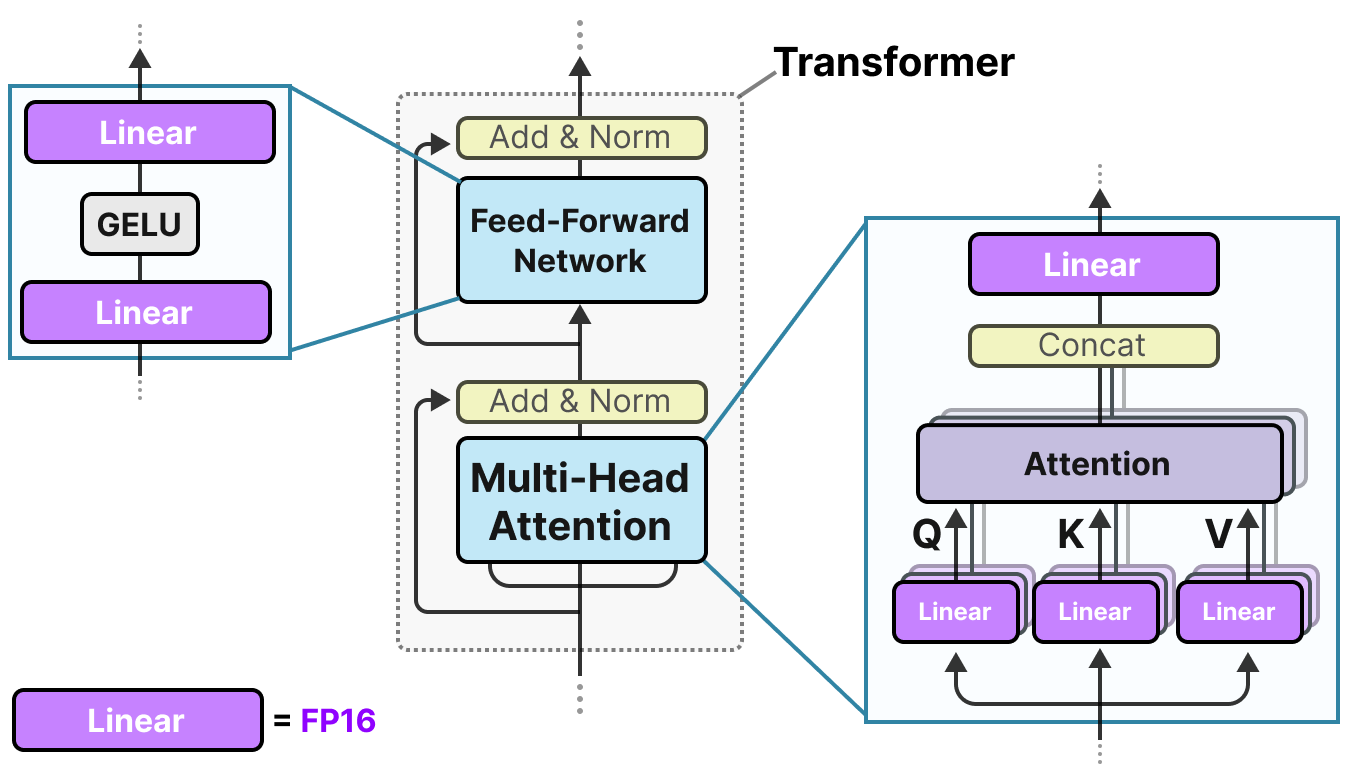
Fast and Accurate GPU Quantization for Transformers
Quantization - Neural Network Distiller
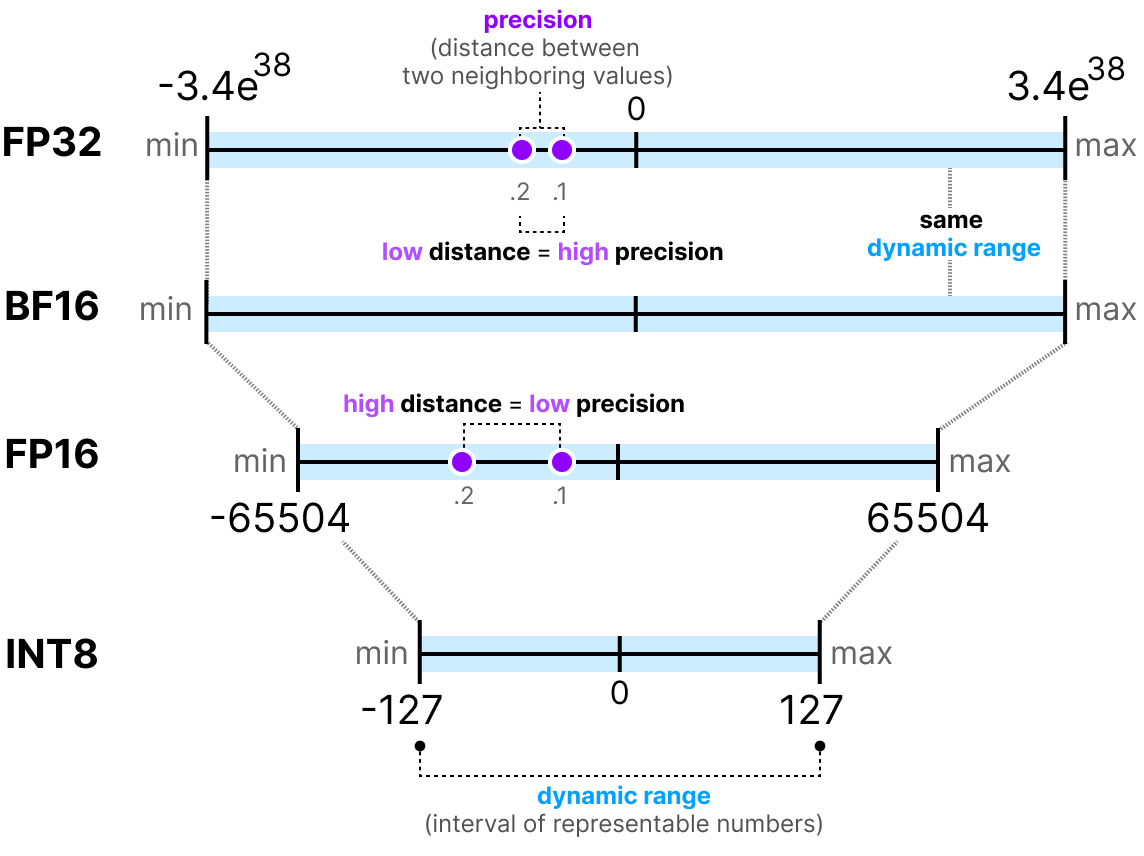
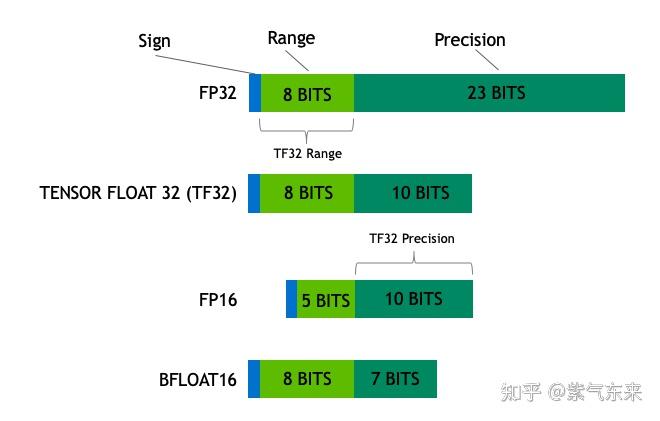
Understanding FP32, FP16, and INT8 Precision in Deep Learning Models ...
This paper is sorta mind blowing🤯 Model quantization has moved from ...
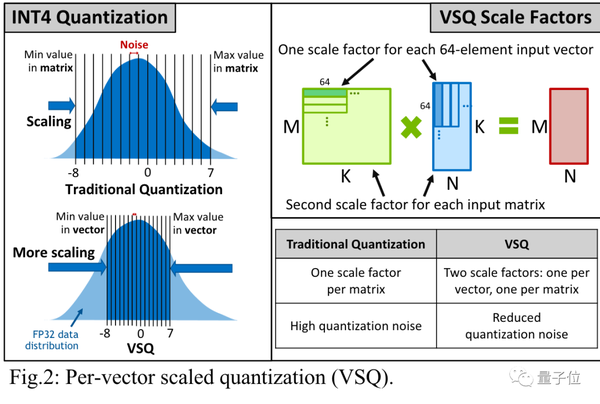
Int4 Precision for AI Inference - Edge AI and Vision Alliance
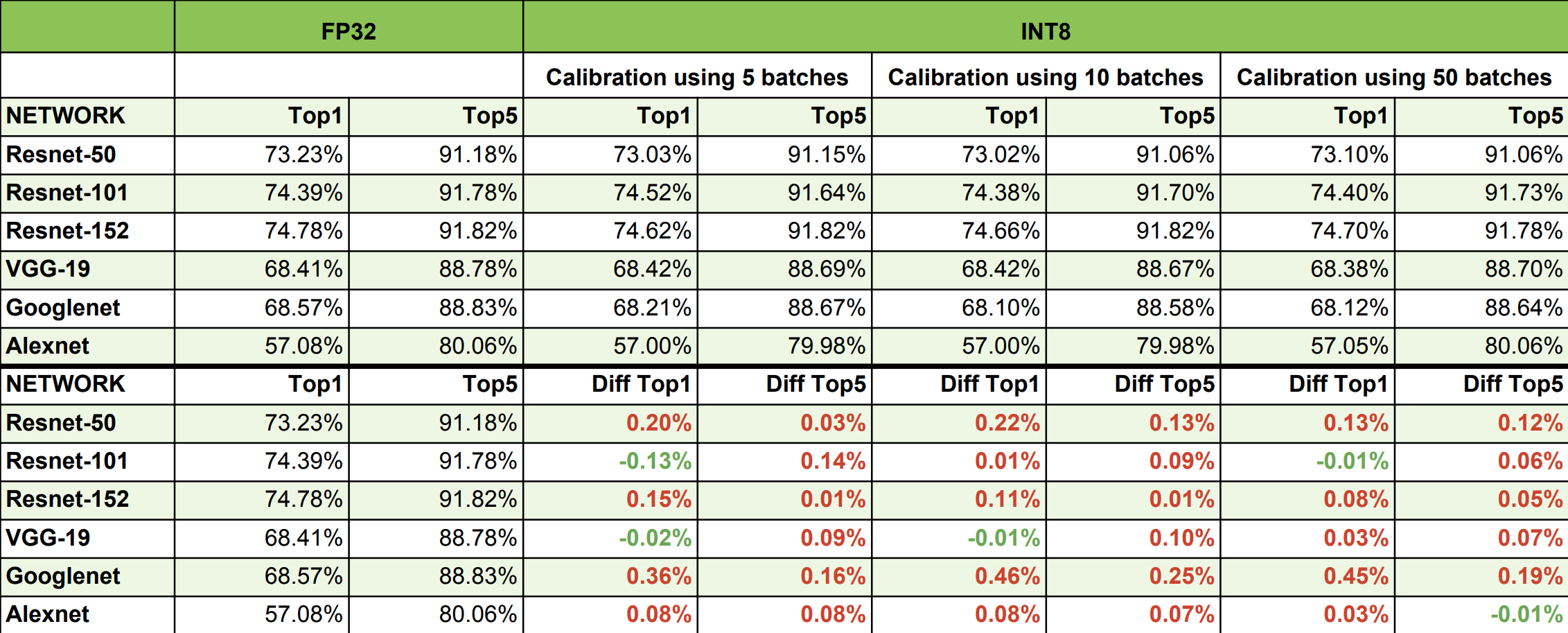
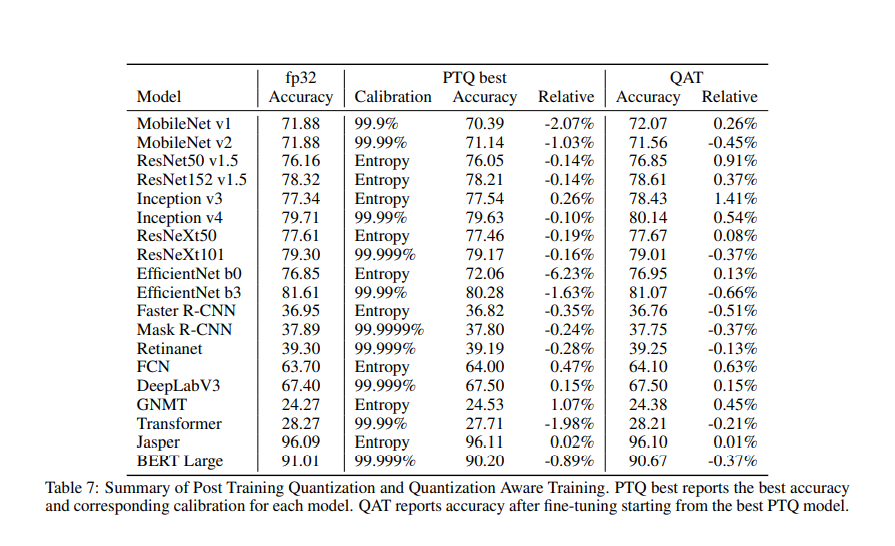
Figure 1 from Performance Evaluation of INT8 Quantized Inference on ...
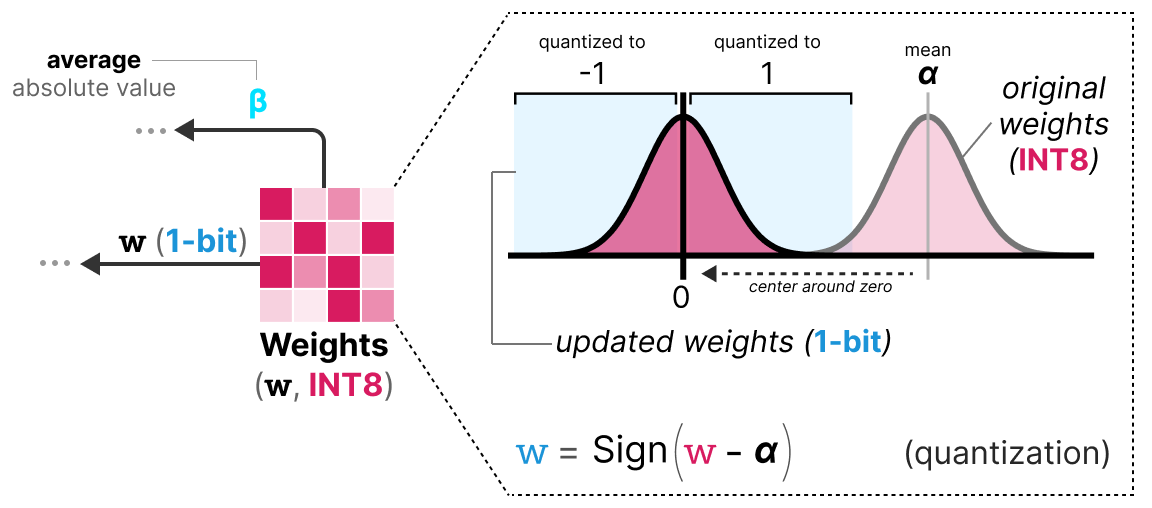
Examples of Quantization Functions. (a) Typical binary (1-bit ...
HAWQ-V3: Dyadic Neural Network Quantization | PDF
Shrinking AI Models by 75%: A Practical Guide to PyTorch INT8 ...
The INT quantization paradigm. | Download Scientific Diagram
7 ML Quantization Wins (INT8/FP8) Without Quality Freefall | by ...
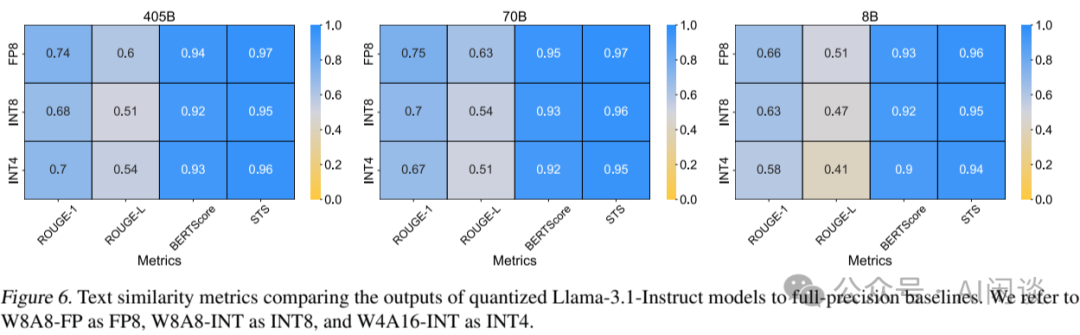
LLM 推理量化评估:FP8、INT8 与 INT4 的全面对比_int4和fp8-CSDN博客
Post-Training Quantization of LLMs with NVIDIA NeMo and NVIDIA TensorRT ...
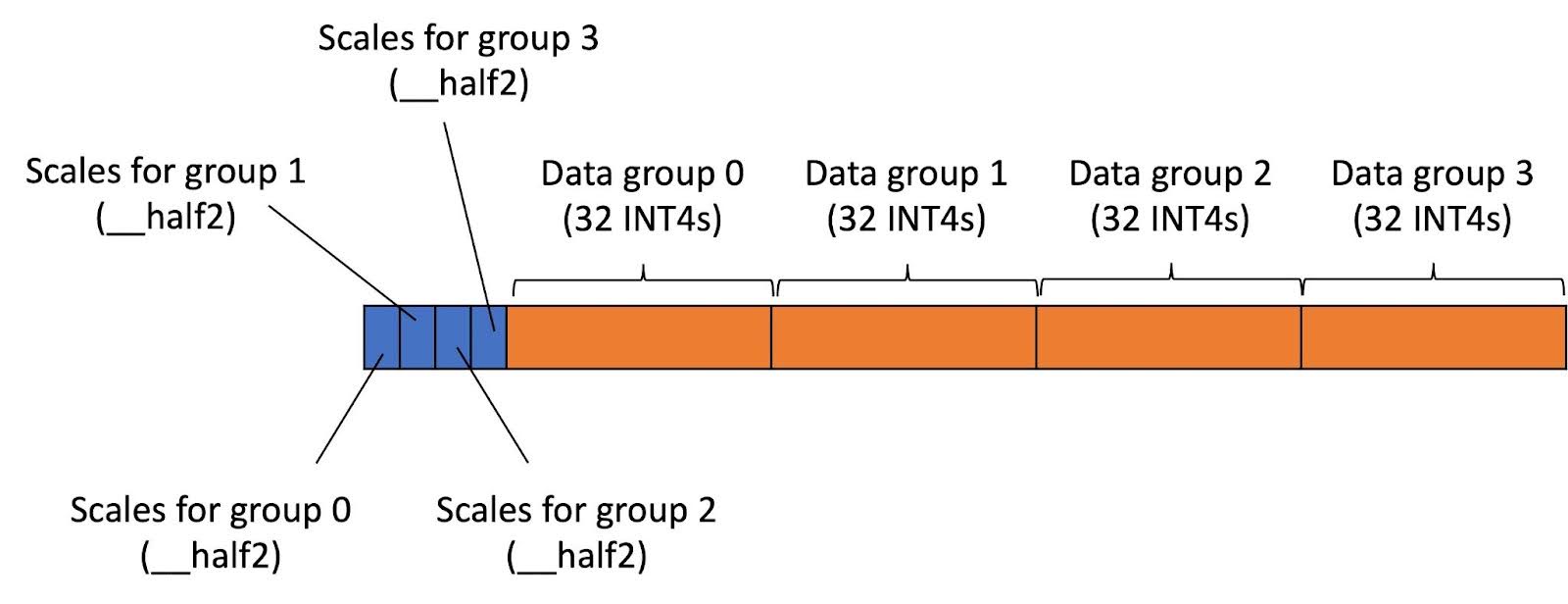
INT4 Decoding GQA CUDA Optimizations for LLM Inference | PyTorch
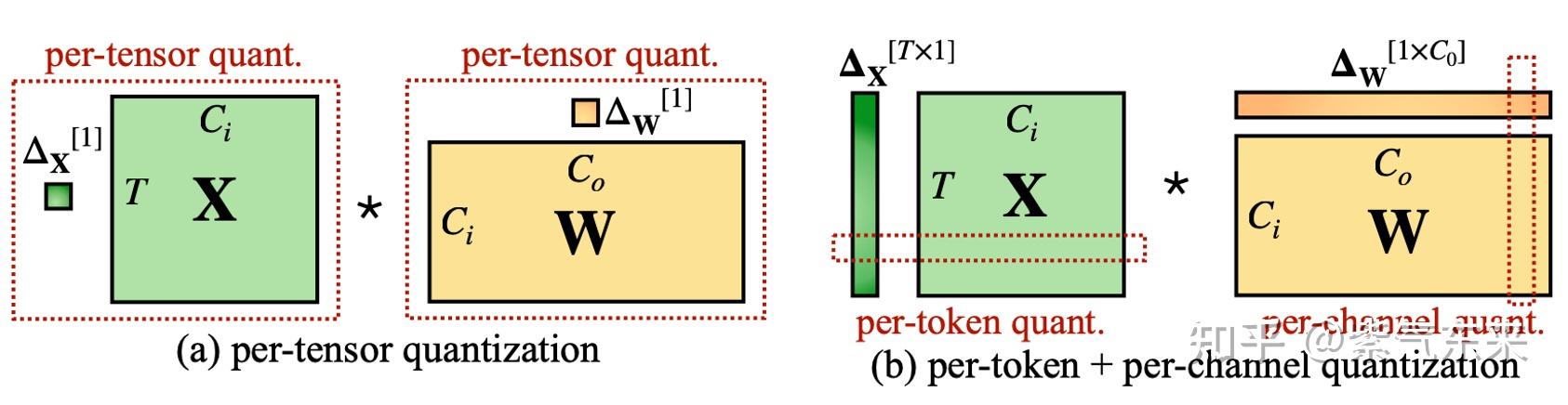
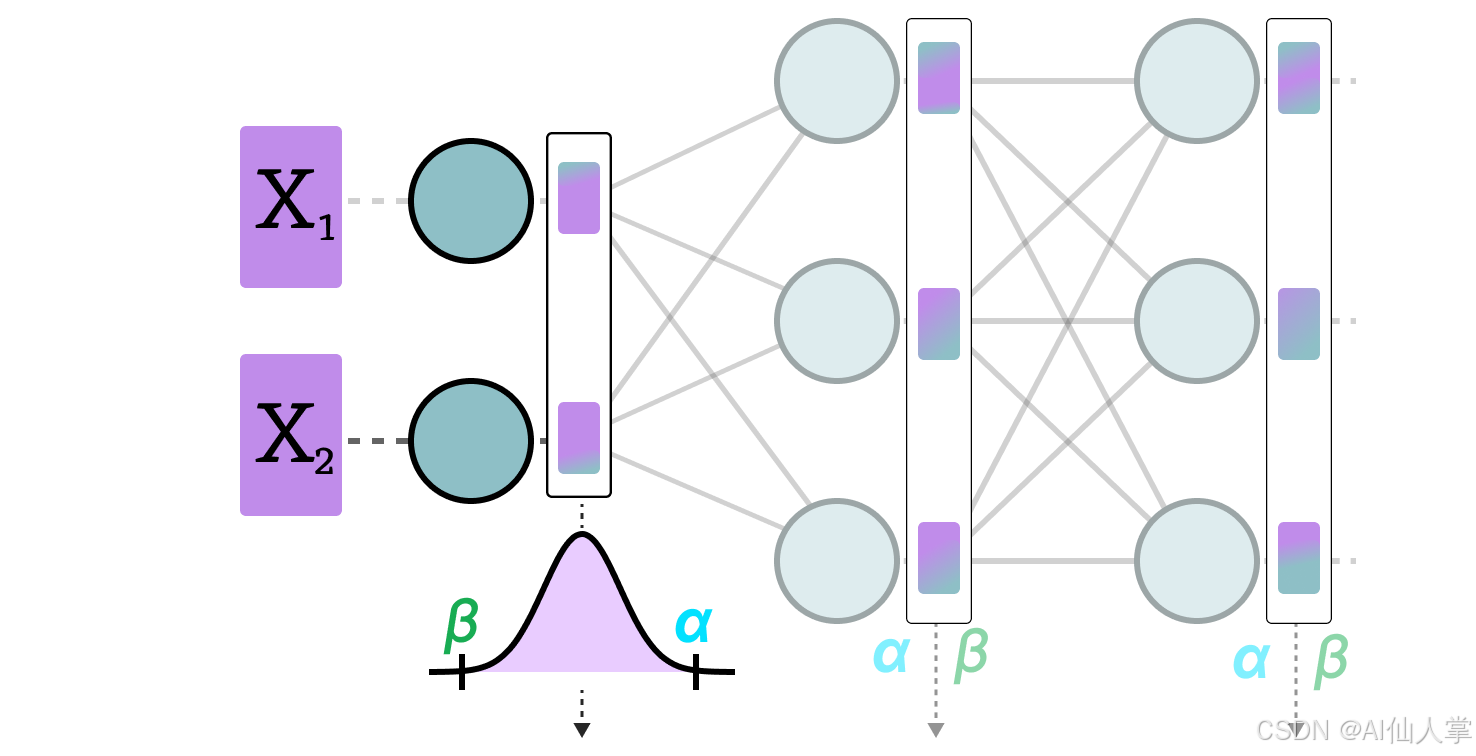
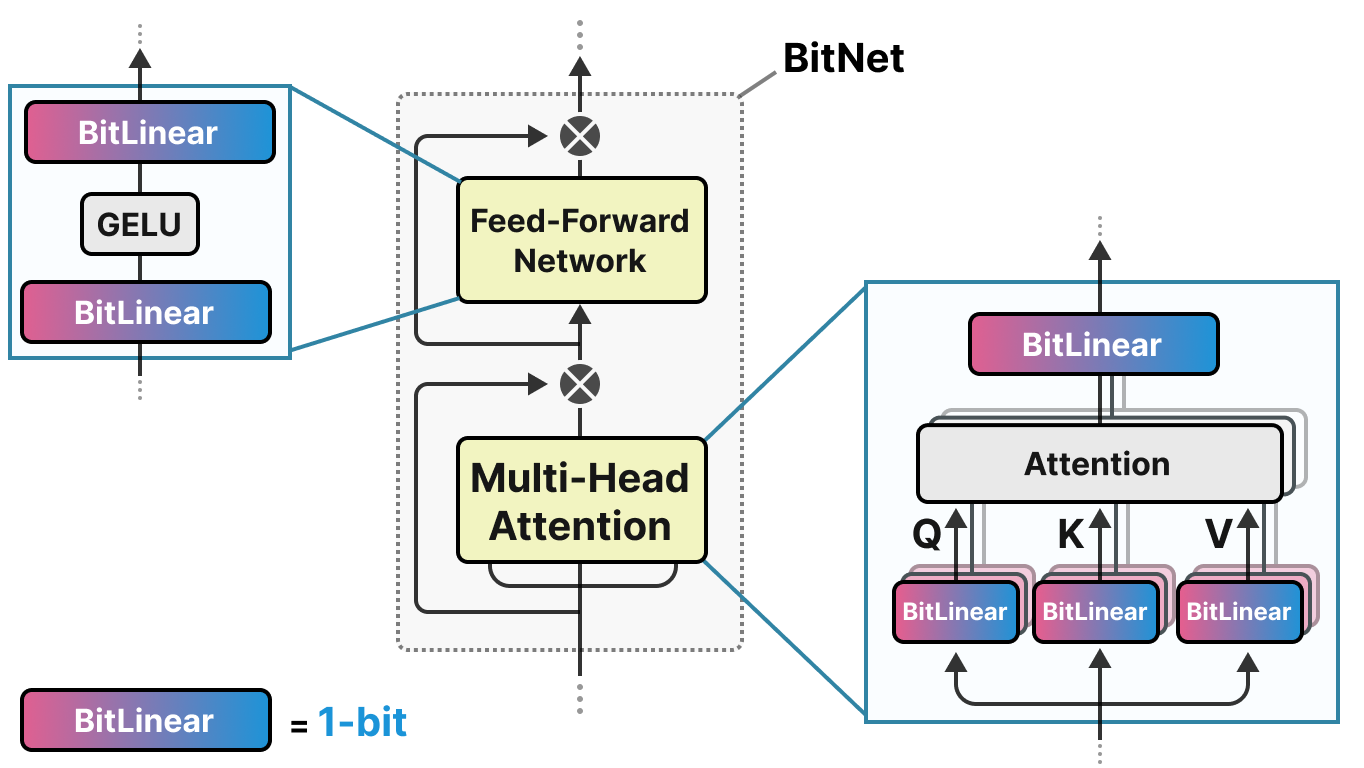
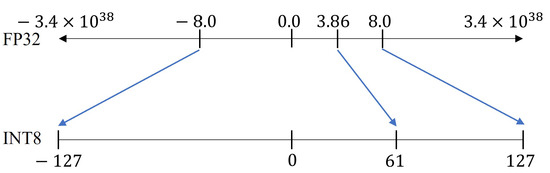
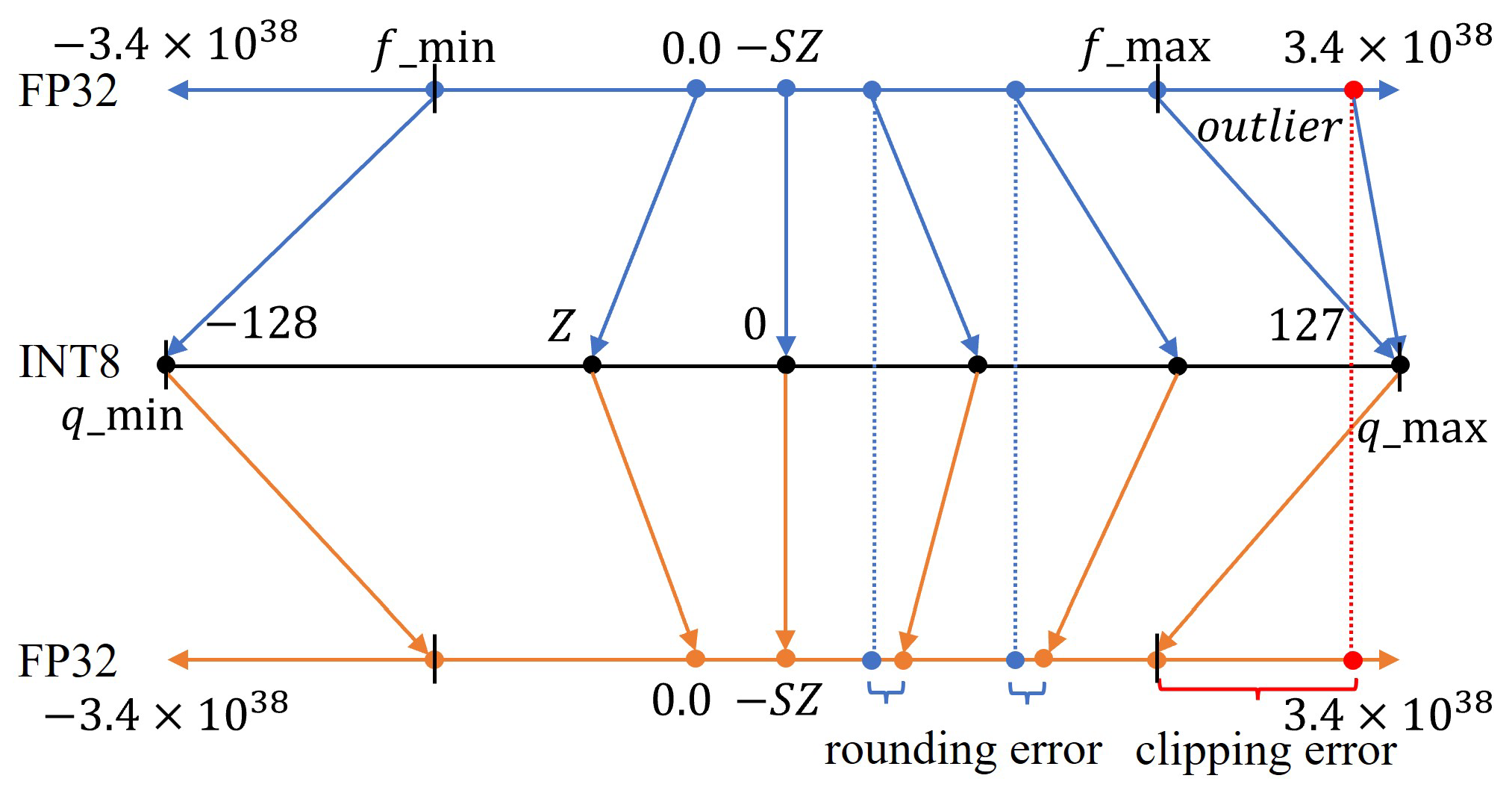
50张图解密大模型量化技术:INT4、INT8、FP32、FP16、GPTQ、GGUF、BitNet_gptq量化-CSDN博客
Serving Quantized LLMs on NVIDIA H100 Tensor Core GPUs | Databricks
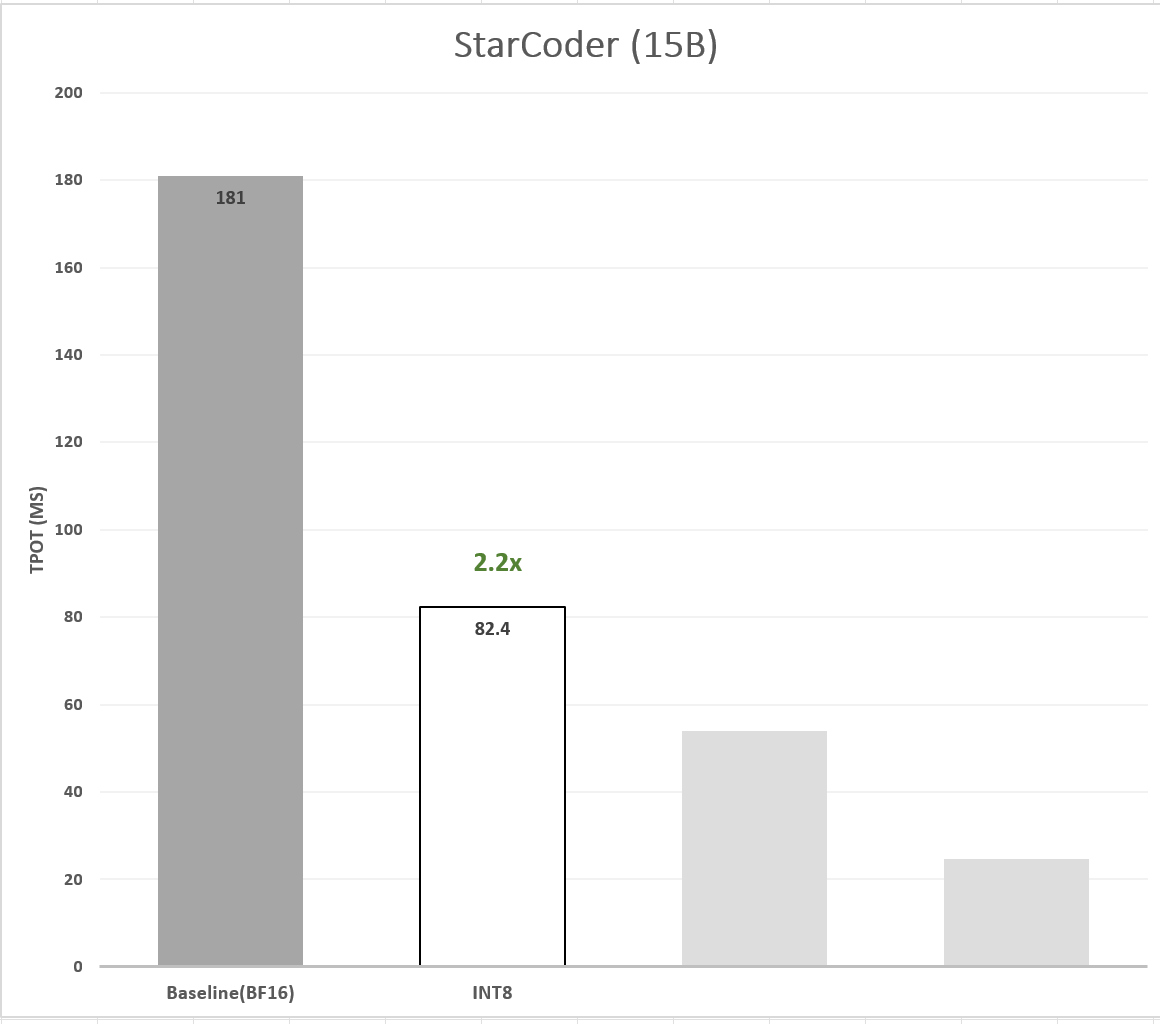
Accelerate StarCoder with 🤗 Optimum Intel on Xeon: Q8/Q4 and ...
LLM(11):大语言模型的模型量化(INT8/INT4)技术 - 知乎
深度学习技巧应用17-pytorch框架下模型int8,fp32量化技巧_pytorch模型int8量化-CSDN博客
英伟达首席科学家:5nm实验芯片用INT4达到INT8的精度,每瓦运算速度可达H100的十倍 - 知乎
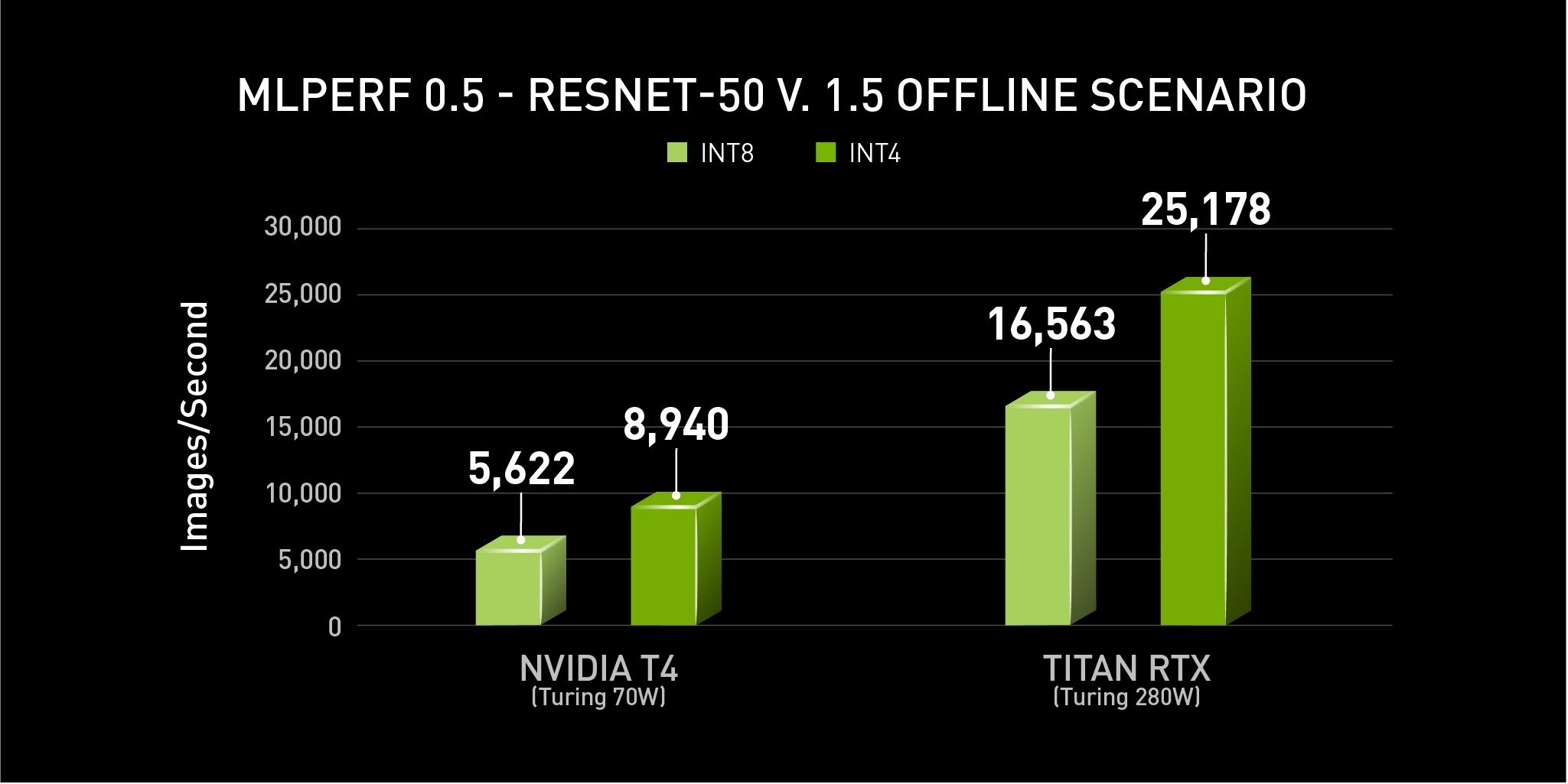
Object Detection on GPUs in 10 Minutes | NVIDIA Technical Blog
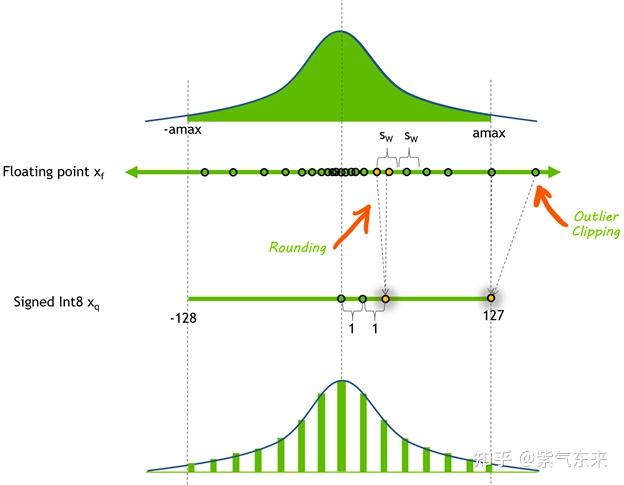
Sparsity in INT8: Training Workflow and Best Practices for NVIDIA ...
LLM(十一):大语言模型的模型量化(INT8/INT4)技术 - 知乎
模型量化(int8)系统知识导读_int4量化-CSDN博客
大语言模型的模型量化(INT8/INT4)技术-CSDN博客
大语言模型的模型量化(INT8/INT4)技术_int8和int4-CSDN博客
BitNet a4.8: 4-bit Activations for 1-bit LLMs · HF Daily Paper Reviews ...
[2307.09782] ZeroQuant-FP: A Leap Forward in LLMs Post-Training W4A8 ...
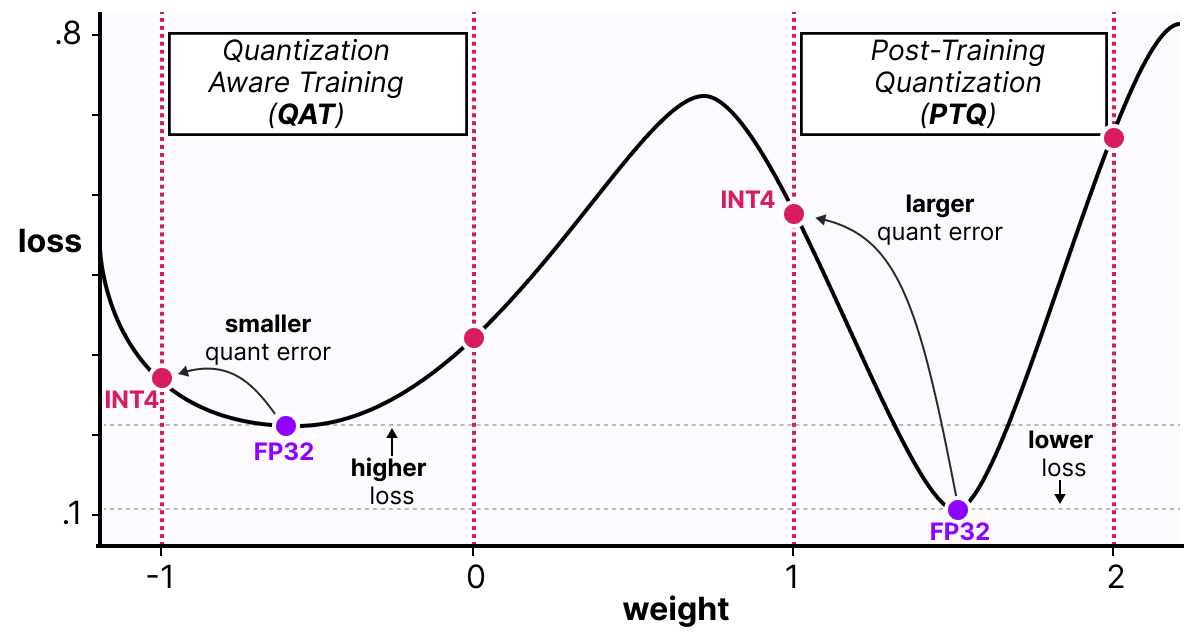
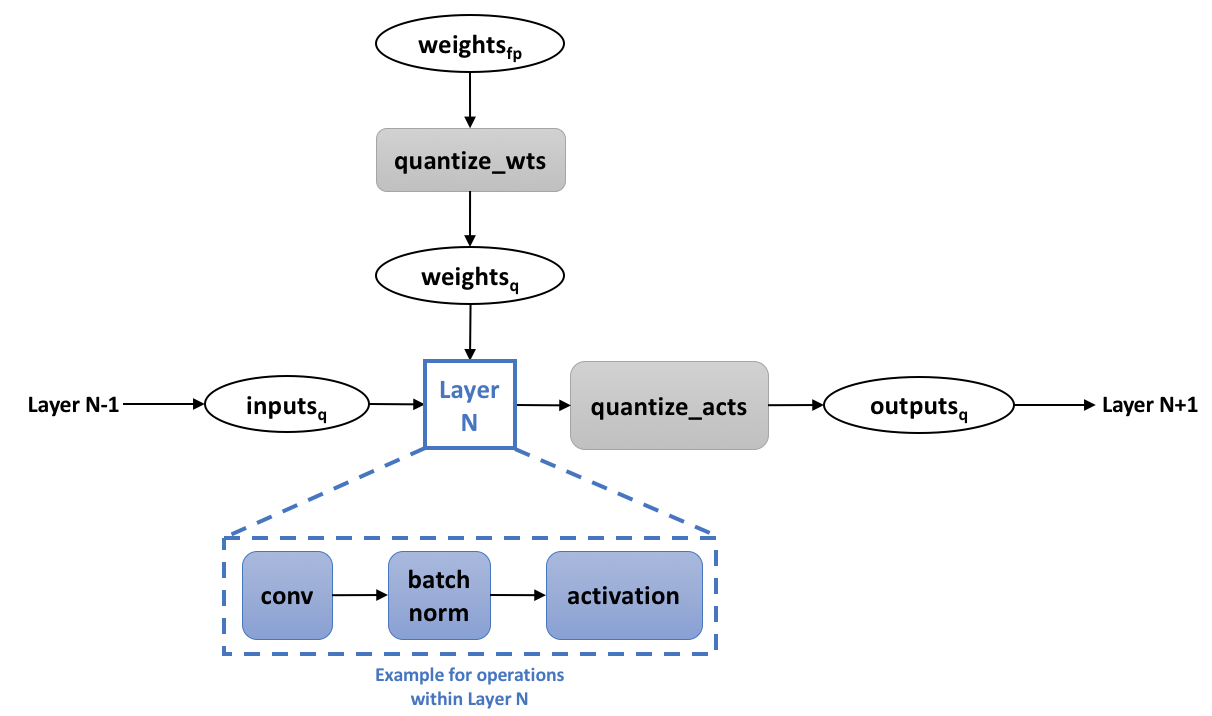
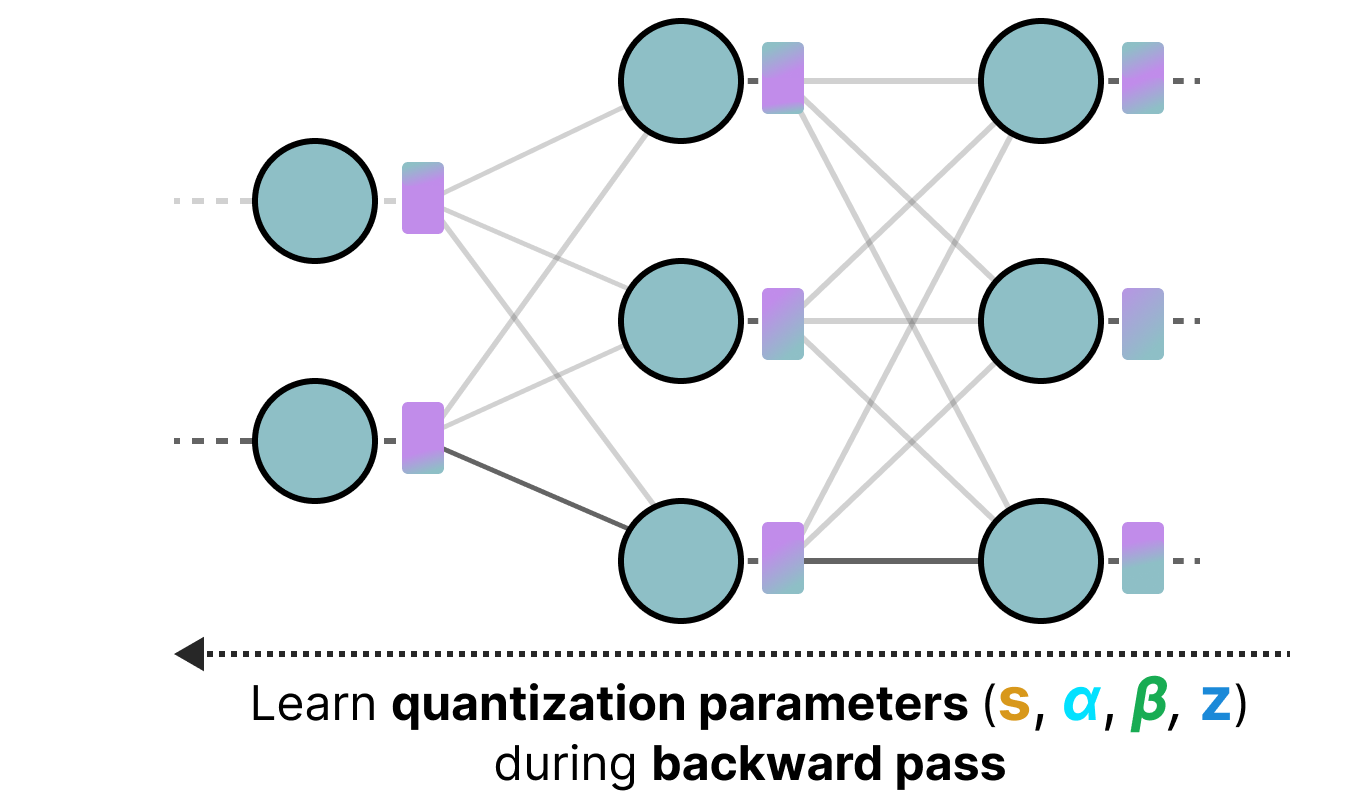
Quantization-Aware Training | AI Tutorial | Next Electronics
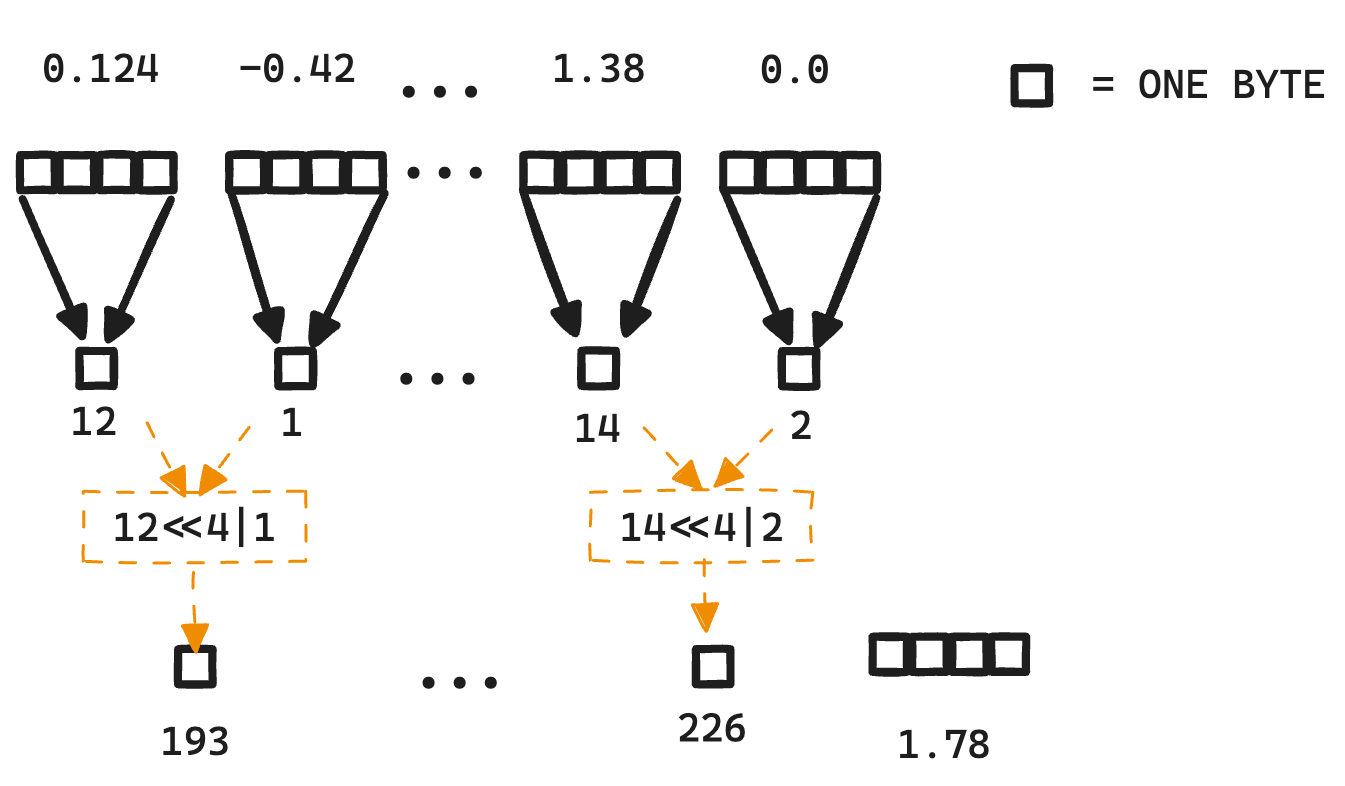
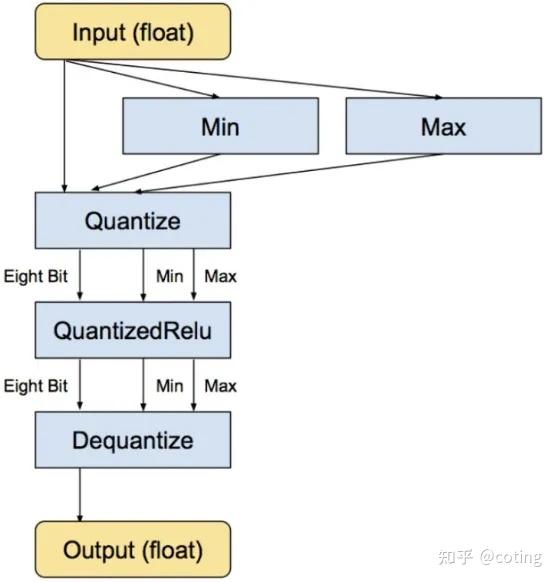
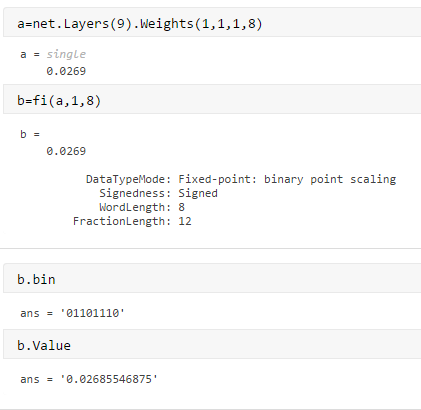
用于量化的INT8、INT4及其他整数类型
Small numbers, big opportunities: how floating point accelerates AI and ...
模型量化大揭秘:INT8、INT4量化对推理速度和精度的影响测试-腾讯云开发者社区-腾讯云
小白也能懂!INT4、INT8、FP8、FP16、FP32量化-CSDN博客
模型量化(int8)知识梳理 - 知乎
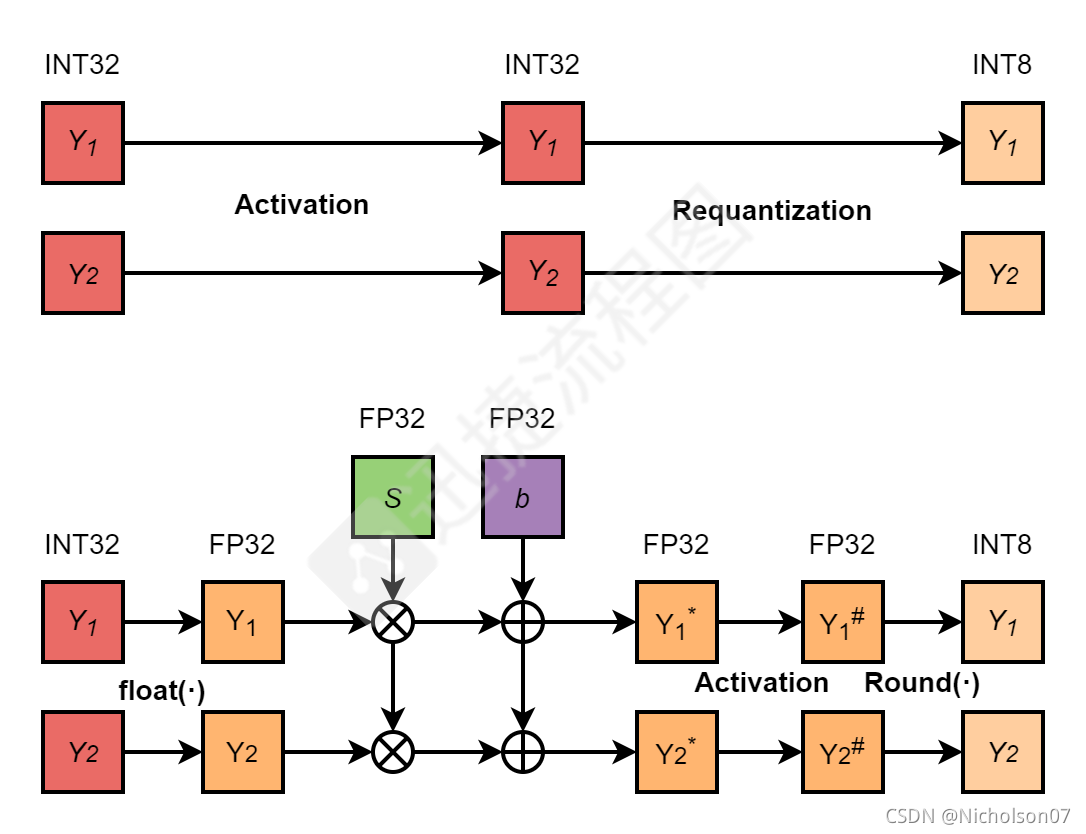
TensorRT INT8量化原理与实现(非常详细)-CSDN博客
Quantization: Reducing Model Precision (FP16, INT8)
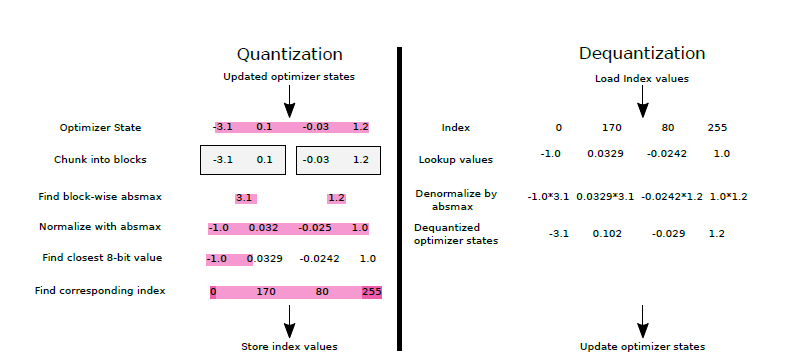
Quantized 8-bit LLM training and inference using bitsandbytes on AMD ...
Deep Learning Performance Characterization on GPUs for Various ...
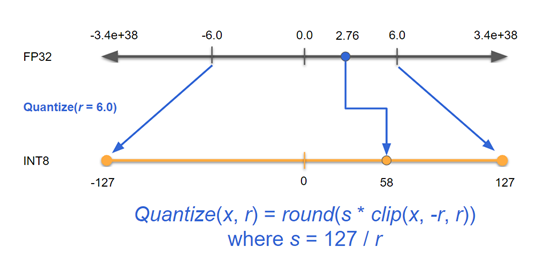
Working with Quantized Types — NVIDIA TensorRT
NVIDIA TensorRT Accelerates Stable Diffusion Nearly 2x Faster with 8 ...